지금 AI가 한계니 뭐니 말이 계속 나오는 이유에 대한 가장 근본적인 이유(스압)

알파고 모르는 유게이는 없을 거라 생각함
알파고 만든데가 구글 딥마인드인데
딥마인드 얘네가 인공지능에 크게 기여한 게 하나 더 있음
알파고가 2016년에 나왔고 그 다음해에

이 논문이 나옴
꺼무에 이 논문의 초록이 번역이 되어있으니 올리자면:
지금까지의 특징을 전달하는(transduction) 모델은 주로 복잡한 순환 신경망(RNN)이나 인코더-디코더같은 합성곱 신경망(CNN) 방식이 우세하지만, 우리는 어텐션을 사용한 '트랜스포머'라는 간단한 모델을 제안한다. 두 가지의 기계 번역 문제에 대해 실험했고, 학습 시간이 매우 적어야 한다는 것과 병렬적이여야 한다는 조건 하에서 상기된 모델이 질적으로 우수함을 보였다. 상기된 모델은 WMT 2014 영어-독일어 번역 문제를 앙상블이 포함된 기존에 존재했던 결과보다 2 BLEU 향상시킨 28.4 BLEU를 달성했다. 영어-프랑스어 번역에서는, 기존 최상 모델들의 학습 비용의 작은 부분 정도인, 8개의 GPU를 활용해 3일 12시간에 걸쳤던 학습을 마친 후 41.8 BLEU의 신규 모델 상태를 지정했다. 또한 한정된 학습 데이터와 방대한 학습 데이터와 함께 영어 파싱(parsing)에 성공적으로 어텐션 방식을 적용함으로써 트랜스포머가 다른 문제들에도 이를 일반화한 것을 보였다.

한줄 요약하면
어텐션을 이용한 트랜스포머 모델을 설명하는 논문임

유게이: 어텐션이랑 트랜스포머가 뭔진 설명해야 한줄요약이 될거 아니야!

그래서 설명하고 있잖아!
아무튼 인공지능 연구가 어떻게 진행되었는지 개략적으로 알아야 하는데
진짜 쉽게 이야기하자면
우리의 신경망을 알고리즘으로 구현해 기계도 생각할 수 있게 만든 프로그램이 "인공신경망"임
대략적으로 어떤 구조인지 설명하자면
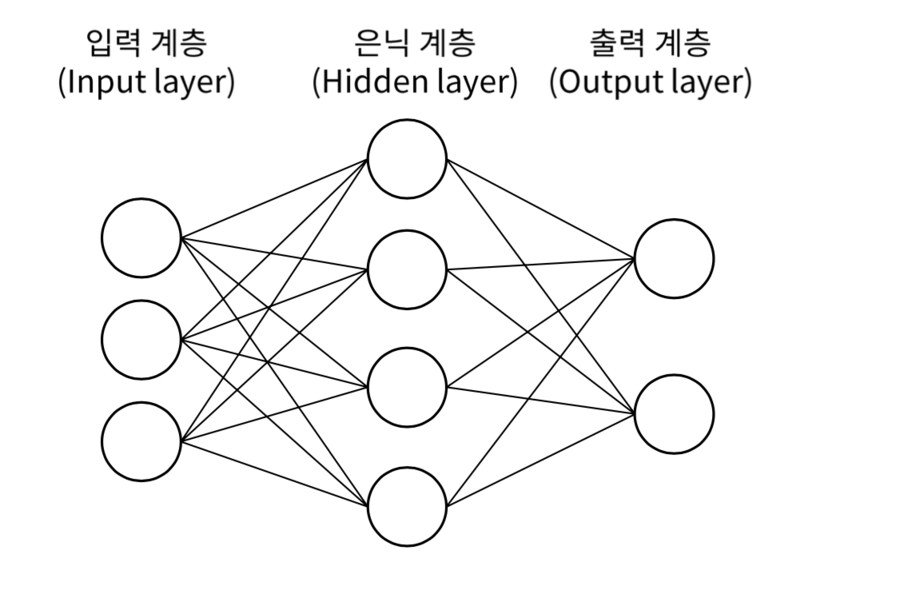
대충 이렇게 굴러가는데
입력층에 정보가 주어지면
은닉층을 거치면서 연산을 해서(그림에서는 하나지만, 은닉층은 보통 수십,수만개가 일반적)
출력층으로 결과가 나오는 구조임
이 은닉층을 거치는 연산에 따라 인공신경망의 성능이 결정되는데
이때 사용되는 매커니즘 중 하나가 아까 위에서 튀어나온 어텐션임
이 어텐션을 이용한 트랜스포머가 획기적인지는 기존의 인공지능 연구를 알아야 함
기존의 인공지능 연구는 RNN, 번역하면 순환 신경망 위주로 연구되어 왔었음(세부적으로 따지면 뭐 세세한거 많지만 일단 큰 갈래가 이쪽)
한마디로 이전 결과를 바탕으로 다음 결과를 처리하는 방식
거기에
2012년에 딥러닝 이론이 나오면서 순환 신경망에 위에서 언급한 은닉층을 엄청 많이 추가해보는 일이 늘었음
아까 은닉층이 수십수백개라고 했는데 딥러닝은 이 은닉층 양이 늘어날 수록 인공 신경망 성능이 좋아진다는 이론임
(참고로 이 딥러닝 이론으로 만든게 바로 그 알파고 맞음 ㅇㅇ)
그렇게 한 방식의 기존 연구의 문제를 정리하자면...
1) 순환 신경망에서 은닉층을 엄청 많이 추가하면 결과가 딴판이 나오는 경우(입력 데이터와 출력 데이터가 서로 관계가 없는 경우)가 많음
2) 은닉층을 많이 계산해야하는데 병렬 계산이 안되서 학습 속도가 오래걸림
이 두가지로 정리가 가능함
그 문제를 어느 정도 잡아준 게 바로 트랜스포머인데
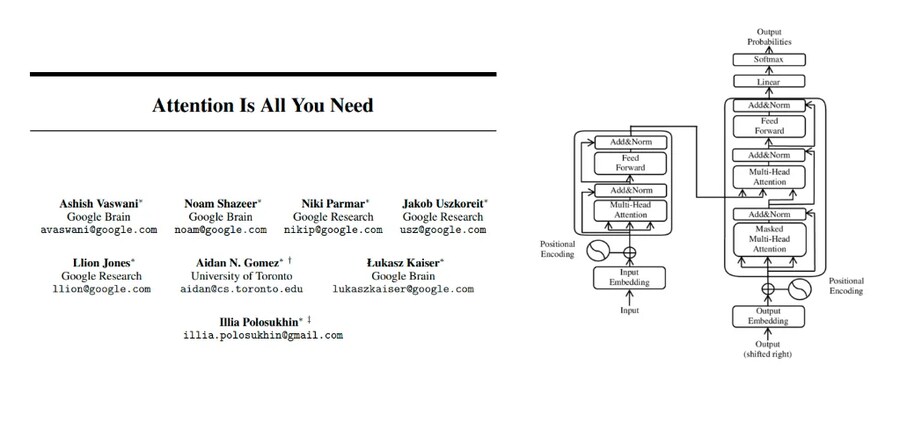
입력 데이터에서 이렇게 중요한 부분을 찾아 강조해서(Attention이라고 쓰여있는 과정이 해당)처리하는 매커니즘인데다,
저 구조를 보면 알겠지만 저거 병렬로 계산하는 구조임
이게 왜 중요하나 싶겠지만
chat-gpt의 GPT가 저 트랜스포머의 디코더만 사용한 모델임
GPT뿐만이 아니라 지금 사용되는 모델은 죄다 저 트랜스포머를 기반으로 만든 모델이라고 보면 됨
그래서 저 논문이 지금 AI의 근간이란 이유인게 저거
유게이: 개선된거면 좋은 거 아니야?
트랜스포머 단점이 없는 건 아님
딥러닝은 은닉층을 늘려서 성능을 올리는데
트랜스포머 모델은 뭘 늘려서 성능을 올리냐면
매개변수와 학습데이터임

매개 변수와 학습 데이터를 늘린다는 말에서 눈치챈 유게이도 있을지 모르겠지만
챗지피티나 제미니가 학습데이터를 웹 상의 거의 모든 데이터를 끌어다 쓰는 상황이기 때문에
그걸로도 모자라 AI 생성 데이터를 끌어와서 성능이 떨어지는 거 아니냐는 이야기가 나오는 게 이런 이유
인류가 여태까지 생성한 데이터를 넘어서 더 많은 양을 학습하려면 뭐로 학습해야 하냐는 질문이 있는데
이걸 AI가 생성한 데이터로 학습하려다 역으로 성능이 떨어진다는 결론이 나왔음 ㅇㅇ
이거 피하려고 추론을 쓰니 뭐니 하는 식으로 이야기를 하고 있는데
이게 근본적인 해결법이었다면 내가 이런 글을 쓰고 있진 않았을 거임
그리고 어중간한 AI란 이야기도 절대 나오지 않았을 것이고
그리고
이건 현실 문제와 직접적인 연관있는 부분인데
AI 학습을 위해 돌리는 메모리나 전력도 꽤 많이 차지하기 때문에
AI 학습을 위한 데이터 센터를 짓고 그 기반시설도 설치하는 데 꽤 많이 투자하고 있음
수도권 전력난 이슈 이야기가 나오는게 저 데이터센터랑 어느정도 연관이 있어서 나오는 이야기기도 하고 ㅇㅇ
국내 이야기는 유게에서 좀만 딥하게 다루면 정떡 튀어나올 가능성이 99.999%니 여기서는 논하지 않기로 하고
미국만 봐도 아예 자체 전력 소비를 줄이기 위해 별 짓을 다하고 있는중이지만
아직 이 해결책도 안 나온 상황임
정리하면
1) AI 데이터 학습할 양은 한정적인데, 벌써 그 데이터 량이 여지껏 전 인류가 생산한 데이터 량에 육박함
2) AI 학습시키고 굴릴 설비를 받을 기반시설이 기존의 설비를 넘어서 전기를 많이 잡아먹는 하마
이 두 가지가 현재 트랜스포머 모델의 문제, 더 나아가 현재 AI가 가진 문제라고 볼 수 있음
???: 강인공지능 나오면 되지 않음?
되겠냐?
저 트랜스포머 모델 나온게 2017년인데 아직도 이걸 넘는 무언가가 안나온 상황에서
위기론이 안나오는게 안 이상하냐고...
물론 강인공지능이 어떤 천재적인 누군가의 발상에서 갑자기 나온다면 또 모르겠다만

이 상태로 3-4년 좀더 진행되면
진짜 어중간한 AI가 인류를 위협할 수 있다는 말이 점점 체감이 올거임...
AI 쓰는 건 유게이 자유지만,
AI 낙관론은 너무 믿지마...
이쪽 연구 주워 듣는 빡통의 시선에서 봐도 뭔가 새로운 게 나오면 다들 그쪽 연구해서 내가 모를 리 없어...
제발 너무 믿지마...

글 3줄요약:
1) 트랜스포머 모델을 2017년부터 우려먹었는데 아직도 이걸 넘는 무언가가 나오지 않음
2) 데이터 양이 유한해서 학습 데이터 양을 늘려서 AI 성능을 올리는데엔 한계가 있음
3) 글쓴이 빡통임