학사레벨 ㅈ문가의 지식이므로 틀린 부분이 있을 수도 있습니다
다른 쓰잘데기 없는 이야기) 반도체 수명과 관련된 일렉트로마이그레이션 현상
https://bbs.ruliweb.com/community/board/300143/read/53362225
공정 미세화와 더 높은 성능을 위해 더 작은 면적에 더 많은 트랜지스터를 때려박게 되면서, 칩의 전류 밀도는 계속 높아져왔다
전류 밀도가 높은 것은 곧 칩의 전력 소모가 높고 동시에 발열도 높아진다는 이야기이므로, 이는 난로를 만드려고 하지 않는 이상 칩에 하등 좋을 것이 하나도 없다
(열이 높을수록 흐르는 전류가 많아지고(=전력 소모가 높아지고), 이는 곧 다시 칩의 발열을 높이는 악순환의 고리를 만든다.
또한 높은 열로 인해 반도체를 구성하는 트랜지스터 자체가 망가질 가능성도 있으며, 트랜지스터를 연결하는 금속 선로에 문제를 발생시킬 수도 있다.)
쉽게 말하면 더 작은 놈이 더 열심히 일하다보니 전력도 많이 처먹고 발열 뿜뿜해서 문제가 된다 이 말이다
이로 인해 반도체 회로 설계자들은 어떻게든 전력 소모를 줄이고자 노력을 해왔는데
그 중 몇가지 이야기를 해보고자 한다
그 전에 우선 클럭 신호에 대해 대충 알고 넘어가야 한다.
CPU든 뭐든 칩의 주요한 성능 지표 중 하나인 클럭은, 디지털 회로의 동기화 신호를 일컫는다
조금 자세히 설명하자면, 현존하는 대부분의 디지털 회로는 낸드, 인버터 등으로 대표되는 콤비네이셔녈 셀로 구성된 콤비네이셔널 회로와 플립플랍과 래치로 대표되는 레지스터와 콤비네이셔널 회로의 조합으로 구성된 시퀀셜 회로로 이루어져있다.
정확한 이해는 아니지만, 콤비네이셔널 셀이 입력에 따라 특정 연산을 수행한다면, 플립플랍은 그 연산된 데이터를 후속 연산에 활용하기 위해 저장 해두는 셈이다
들어오는 데이터를 콤비네이셔널 회로에서 연산하고, 그 연산한 값을 레지스터에 저장하고, 다음 콤비네이셔널 회로에서 연산해서 다시 그 데이터를 다음 레지스터에서 저장하고... 이런 과정을 거쳐 최종 연산을 출력하는 구조라고 생각하면 된다
이 때 콤비네이셔널 회로를 구성하는 한 셀에서 입력이 변하면 연산하는데 걸리는 시간이 필요하고, 연산된 신호가 다음 셀로 전달되는데 걸리는 시간이 존재한다
이 시간이 셀 종류마다 제각기 다르고, 이로 인해 연산이 꼬일 수 있다.
따라서 연산이 완전히 완료됐다고 판단했을 때 데이터를 레지스터에 저장해야하는데, 이 때 레지스터에 일정 주기마다 데이터를 갱신하라고 보내는 동기화 신호가 바로 클럭 신호이다.
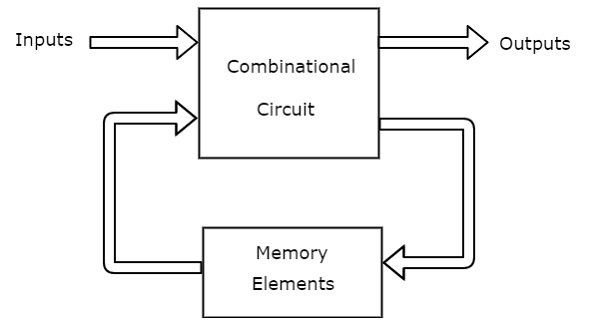
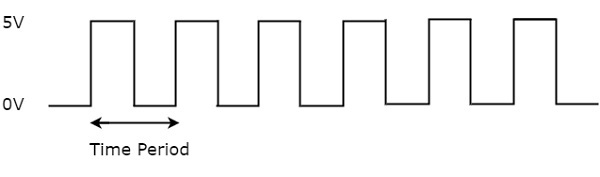
시퀀셜 회로의 블럭 다이어그램(위)과 클럭 신호(아래)
여하튼, 이 클럭 신호가 자주 토글할 수록(=클럭의 주파수가 높을수록), 레지스터들은 더 자주 데이터를 갱신하여 다음 레지스터로 데이터를 전달할 수 있고, 이는 곧 동일한 시간 내에 더 많은 데이터를 처리할 수 있다는 이야기가 된다.
오버클럭은 이 클럭의 주파수를 빠르게하는 것이고
(다만 클럭을 무작정 높일 수 없는 이유는, 콤비네이셔널 회로에서 연산하는데 소요되는 시간이 존재하고, 그 중 연산이 제일 느린 놈을 기준으로 클럭을 맞춰야하기 때문이다)
그리고 당연하겠지만, 이러한 트랜지스터로 구성된 셀은 입력이 바뀌고 연산을 할 때 에너지, 즉 전력을 소모한다.
일반적인 CMOS 디지털 회로에서 소모하는 전력은 다음과 같은 3가지 종류로 구분한다.
1) 입력이 바뀔 때 잠깐 nMOS와 pMOS가 같이 켜지는 순간에 발생하는 단락 전류(short circuit current) 등으로 인해 셀 내부에서 소모하는 internal power
2) 출력단에 존재하는 각종 캐퍼시터(금속 선로나 다음 셀의 게이트 캡 등등...)을 충방전 시키기 위해 소모되는 switching power
3) 아무런 동작을 하지 않을 때도 조금씩 흐르는 누설 전류로 인해 발생하는 leakage power
이 세가지 분류는 보통 반도체 설계 시 사용하는 eda 툴에서 분석시 사용하는 구성이고, internal power와 switching power는 동작시에 소모되는 전력이기 때문에 보통 이 두가지를 묶어서 dynamic power라고 말한다.
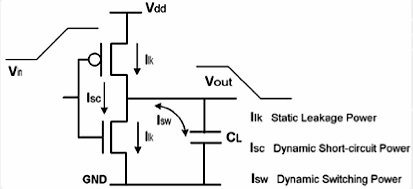
CMOS 인버터 셀에서 소모하는 파워 종류
클럭이 높아진다 = 연산을 더 자주 한다는 것은 입력이 더 빨리 바뀌고, 출력도 자주 바뀐다는 이야기이므로 당연히 셀이 소모하는 전력이 많아지고, 전체적인 칩이 소모하는 전력이 많아진다는 것을 의미한다. 그래서 클럭 주파수가 높아지면 파워를 더 많이 먹는 것이다.
그러니 결론을 내리자면, 일반적으로 반도체 칩이 소모하는 전력은 칩의 클럭 주파수와 칩을 구성하는 트랜지스터의 개수, 칩에 공급되는 전압에 비례한다고 생각할 수 있다.
그렇다면 칩이 소모하는 전력을 줄이려면 어떻게 해야할까?
1) DVFS/DFS
DVFS는 Dynamic Voltage Frequency Scaling, DFS는 Dynamic Frequency Scaling의 준말로, '그럼 칩 성능이 그렇게 많이 필요하지 않을 때 클럭 주파수를 유동적으로 변경하면 되지 않을까?'라는 개념이다.
노트북 사용하다보면 클럭이 막 지멋대로 변경되는 것을 볼 수 있는데, 그게 이거라고 보면 된다.
게임을 할 때와 달리, 웹서핑을 할 때 CPU는 그렇게 많은 연산 능력을 필요하지 않을 것이며, 이는 다르게 말하면 클럭 주파수가 그리 높지 않아도 된다는 이야기다.
이러한 관점에서 접근한 것이 DVFS와 DFS로, DFS는 사용 시나리오에 따라 클럭 주파수만 줄이는 것, DVFS는 사용 시나리오에 따라 클럭 주파수와 동시에 공급 전압도 줄이는 것을 말한다.
이는 어떻게 보면 소프트웨어적인 접근으로, 현재 칩의 사용률을 고려하여 칩 내부에서 사용하는 클럭과 공급 전압을 컨트롤하는 방법이라고 생각하면 될 것이다.
2) 클럭 게이팅
칩 내부에서도 여러가지 기능을 수행하는 블럭으로 구분되어 있을 것이고, 현재 어떤 작업을 하느냐에 따라 어떤 블럭은 동작하고 어떤 블럭은 동작하지 않을 것이다.
예시를 들자면, 읽기와 쓰기를 동시에 할 수는 없는 기능 블럭에서는, 읽기 동작을 할 때 쓰기 동작을 하기 위한 회로가 동작하지 않을 것이다
그리고 입력 데이터가 변하지 않더라도, 클럭이 공급되는 것만으로도 이 회로는 전력을 소모하고 있다. 이는 출력이 변하지 않더라도 입력이 변하는 것만으로도 내부 트랜지스터 동작이 달라지므로 셀은 전력을 소모하기 때문이다.
가령, 입력이 2개인 AND 셀을 생각해보자. AND 셀은 입력 중 하나가 0으로 고정되어 있다면 출력은 항상 0이 된다. 하지만 다른 입력이 바뀌면, 해당 입력과 연결되어 있는 트랜지스터의 동작이 바뀌기 때문에 최종 출력은 변하지 않더라도 전력을 소모한다. 이는 플립플랍과 같은 레지스터도 마찬가지이다.
또한 클럭 신호를 퍼트리기 위한 셀(CTS, Clock Tree Synthesis)도 존재하며, 모든 신호 중에서 클럭은 가장 빨리 토글하는 신호이기 때문에 이들이 소모하는 전력이 어마무시하다
그럼 읽기 동작을 할 때는 쓰기 동작을 하는 회로에는 클럭을 끊어버리면 전력 소모가 줄어들지 않을까?
이러한 개념이 바로 클럭 게이팅으로, 보통 클럭 게이팅 셀은 아래와 같은 구조를 사용한다.
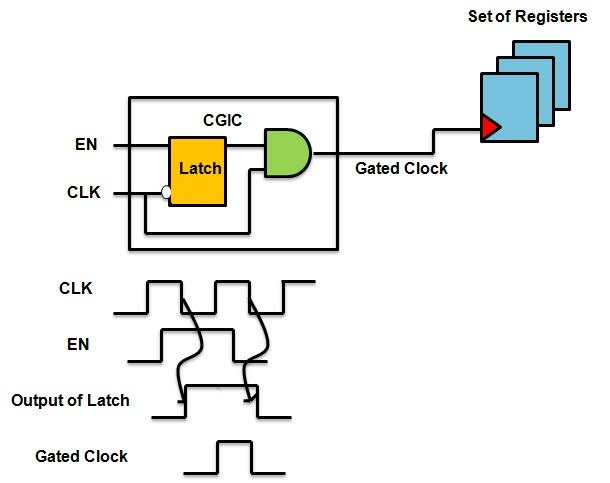
클럭 게이팅 셀의 구조와 동작 다이어그램
하지만 너무나 당연하게도 이 클럭 게이팅 셀만 들어가지는 않을 것이고, 클럭 게이팅을 컨트롤하는 회로가 또 필요해진다.
즉 회로의 구성이 복잡해지는 것이며, 이는 셀의 개수가 증가하는 것을 말한다.
그래서 클럭 게이팅을 포함한 설계를 할 때는 이 클럭 게이팅으로 과연 얼마나 많은 회로에 클럭을 끊을 수 있을지, 또 이 클럭 게이팅을 위해 어떻게 컨트롤하는 회로를 설계할지 고민해야한다. 레지스터 서너개에 공급되는 클럭을 끊자고 클럭 게이팅을 컨트롤 하기 위한 연산 회로로 레지스터 두세개가 추가되면 말짱 꽝이지 않은가?
쉽게 말하면 배보다 배꼽이 더 커지지 않도록 고민해야한다는 이야기다.
3) 파워 게이팅
위의 두 경우는 dynamic power에 대한 접근 방법이라면, 파워 게이팅은 leakage power를 줄이기 위한 접근 방법이다.
클럭 게이팅이 클럭을 끊어버리는 것을 의미했으니 파워 게이팅이라는 이름만 들어도 알 수 있겠지만, 이건 칩이 동작할 필요가 없을 때 회로에 전압 공급을 끊어버리는 기능을 추가하는 것이다. 전압 공급을 끊어버리면 아예 전력 소모를 안할테니까
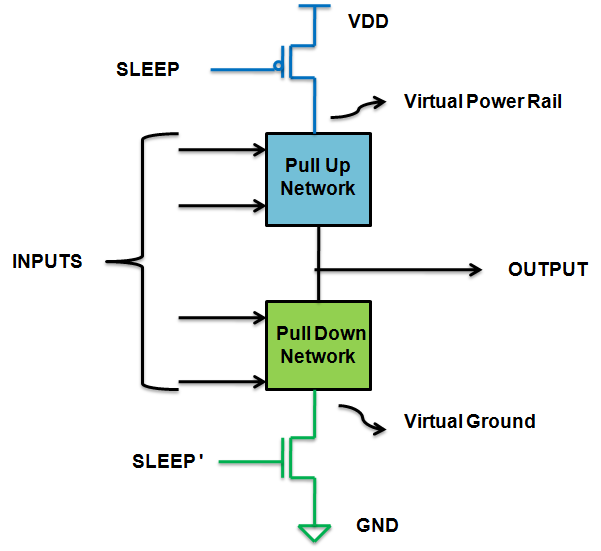
물론 이 친구도 마냥 이득만 있는 것이 아니니, 클럭 게이팅과 마찬가지로 이 동작을 컨트롤하기 위한 부가 회로가 필요해진다.
그리고 또 하나는, 셀 자체의 특성이 구려진다는 것이다.
보통 트랜지스터는 스위치로 표현하긴 하지만, 으레 그렇듯 트랜지스터 자체도 결국 저항과 캐퍼시터로 구성되며 이는 신호가 빠르게 전달하는 것을 막는 소자이다.
즉 셀을 구성하는 트랜지스터가 스택될수록 셀이 느려진다. (여담이지만, 복잡한 연산을 하기 위한 셀을 하나로 만들어버리면 이러한 점 때문에 셀 하나가 연산할 때 걸리는 시간이 길어진다. 복잡한 연산을 처리하는 셀 하나 vs 여러 단계에 걸쳐 단순한 연산을 하는 셀로 구성한 회로에서 되려 전자가 불리한 경우가 심심찮게 있다)
본래라면 셀의 기능을 구현하기 위한 트랜지스터만 있어도 됐을 것을 공급 전압을 컨트롤하기 위한 트랜지스터가 추가됐으니 당연히 이 트랜지스터로 인해 다른 트랜지스터에 공급되는 전압에 영향을 끼치게 될 것이다.
셀 특성이 구려지면(=속도가 느려지면) 클럭 주파수를 올리기 힘들어지고, 원래라면 누설 전류가 적은 셀을 쓸 수 있었는데 이것때문에 누설 전류가 큰 셀을 사용하는 경우가 발생할 수도 있다.
(반도체를 구성하는 트랜지스터의 속도는 공급 전압과 트랜지스터의 on/off를 결정하는 문턱 전압의 차이에 비례하는데, 문턱 전압을 낮추면 트랜지스터의 성능을 올릴 수 있지만, 누설 전류가 커지는 문제가 발생한다.)
4) 마진 제거을 위한 오동작 검출/수정 회로
다른 물품들도 그렇지만, 반도체 칩도 마찬가지로 생산 당시 조건과 공급되는 전압과 온도 등 항상 조건이 일정할 수 없으므로,
극한 조건에서의 오동작을 막기 위해 실제 제품이 목적으로 하는 성능보다 추가 마진을 두고 설계를 하게 된다. (오버 클럭은 이 추가 마진을 끌어내는 것이라고 보면 된다. 그걸 위해서 쿨러, 보드 등 좀 더 신경 쓴 부품으로 안정적인 조건을 마련해주는 것이고)
그리고 매우 안타깝게도, 이 추가 마진으로 인해 부득이하게 더 많은 셀과 전력 소모가 더 큰 셀을 사용하게 된다.
여기서 발상의 전환이 들어가는데, 오동작 자체를 막는 것이 아니라, 오동작해도 그걸 검출해서 알아서 수정하거나 다시 연산하게 만들면 되는거 아냐? 라는 접근 방법이 등판하게 된다.
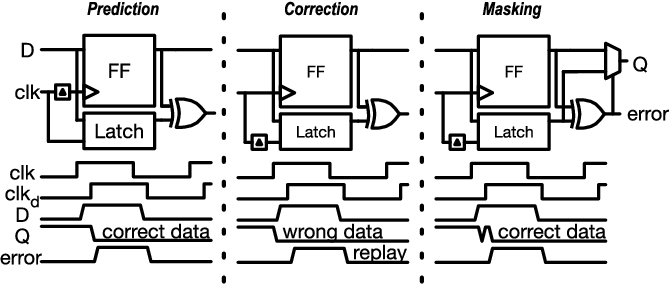
Margin Elimination Through Timing Error Detection in a Near-Threshold Enabled 32-bit Microcontroller in 40-nm CMOS
라는 논문. 일반적인 플립플랍에, 추가 셀을 집어넣어서 오동작을 검출해버리겠다 라는 접근 방법이다.
물론 당연히 이것도 이러한 오동작을 검출/수정하는 추가 회로가 필요해지는 문제가 있다.
5) ASV (Adaptive Supply Voltage)
반도체 관련 공부를 좀 해본 사람이라면 PVT 코너라는 것에 대해 익히 들어보았을 것이고, 그렇지 않더라도 컴퓨터에 관심이 있는 사람이라면 익히 수율이라는 단어를 들어본 적이 있을 것이다. 사실 후자에서 말하는 수율의 경우 일반적으로 말하는 성공적으로 동작하는 비율이라는 의미의 수율이 아니라 4)에서 말한 남아있는 마진으로 끌어낼 수 있는 성능의 여력이라는 수율을 말하는거긴 한데...
PVT(Process, Voltage, Temperature) 중 전압과 온도는 동작 환경에 따라 유동적으로 변할 수 있으니 그렇다치고, Process의 경우 일반적으로 생산 레벨에서 결정되므로 변경되는 일은 없다고 봐야한다. Process 코너가 뭐냐면, 반도체 생산 중 들어가는 도핑 물질의 농도나 게이트의 넓이나 게이트의 두께 등등 여하튼 생산 중 각종 요인으로 인해 발생하는 트랜지스터의 문턱 전압(=성능)의 산포 범위 정도로 이해하면 된다.
일반적인 CMOS 구조에서는 nMOS와 pMOS가 따로 있으므로, 보통 아래 그림과 같이 nMOS/pMOS 순으로 FF(fast fast), SS(slow slow), SF(slow fast), FS(fast slow) 로 분류한다
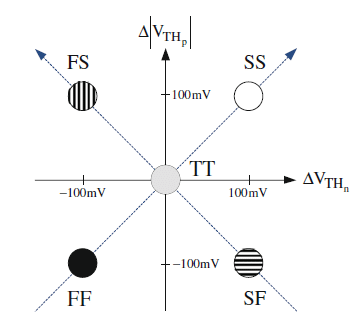
위에서 잠깐 말했지만 트랜지스터의 속도는 공급 전압과 문턱 전압에 비례하므로, FF 코너는 문턱 전압이 낮고 SS 코너는 문턱 전압이 높은 친구들이다.
무작정 느린게 안좋다고 말할 수 없는게 문턱 전압이 낮으면 누설 전류도 같이 커지고 문턱 전압이 높으면 누설 전류가 줄어든다
대충 타겟 성능이 100이면 110을 뽑아내는 애들이 있고 90을 뽑아내는 애들이 있다는건데
ASV는 이 점에 착안해서 110인 애들은 공급 전압을 줄여 소모 전력을 줄이고, 90인 애들은 공급 전압을 높여 성능을 100에 맞추겠다는 개념이다
따지고보면 전력 소비를 조절하기 위한 방법이 아니라 수율 컨트롤 개념에 가깝긴 하다
이런거보면 사실 TT 코너가 짱이다. 성능과 전력 소모 사이에서 밸런스 잡은 애들이거든
역시 중간만 가는게 최고야
여담으로 핀펫(FinFET) 이전의 플래너펫 구조에서는, 바디 이펙트(Body effect)를 이용해 바디에 걸리는 전압을 조절, 문턱 전압을 조절하여 성능/전력 소모 사이에서 밸런스를 잡는 ABB, Adaptive Body Biasing이라는 방법도 존재한다.
논문보다 원인은 까먹었는데, 핀펫 구조에서는 구조 특징 상 바디에 전압 걸어도 문턱 전압에 크게 영향이 없어 핀펫에서는 효용성이 없다고 한다.
이건 진짜 3줄 요약.. 아니 3문단 요약 좀...
전력 소모를 줄이기 위해서 1. 전압과 클럭 주파수를 유동적으로 변경하거나 2. 안쓸때 클럭을 죽이거나 3. 안쓸때 전압 공급을 멈추거나 4. 마진을 빼기 위해 오류 검출 회로를 추가하거나 5. 수율 컨트롤을 한다
아 컨버터 시스템이랑 같은 개념이구나!
컨버터 시스템에 오류 검출 회로랑 수율 컨트롤을 안 할 거 같지만..
대충 모르겠어 하는 서벌쟝