

엔비디아야 워낙에 양아치식 장사한다는거 일반 소비자들이라면 다 아는 사실이지만
사실 엔비디아의 진짜 남는 장사는 게이밍용 그래픽카드가 아님
엔비디아 그래픽카드 중에서 일반 소비자들이 현재 구매할 수 있는 가장 비싼 그래픽카드는 아마 이 TITAN RTX일 것이다.
그러면 TITAN RTX의 스펙을 보자
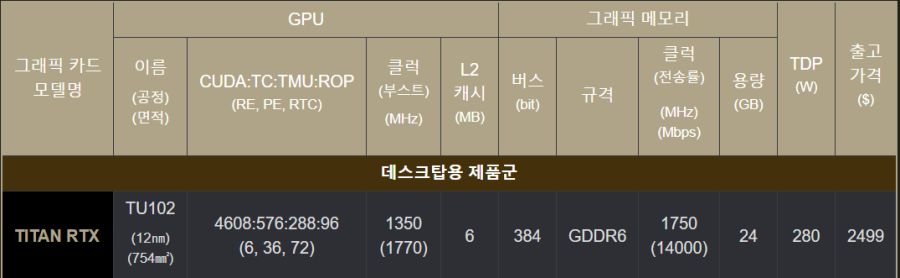
칩셋은 TU102로 RTX 2080 Ti랑 동일한 칩셋을 쓰고 클럭 부스트도 RTX 2080 Ti랑 똑같은 1350MHz이다
부스트하면 RTX 2080 Ti의 1635MHz보다 조금 높은 1770MHz임
CUDA 코어의 수는 4608개로 RTX 2080 Ti의 4305개보다 좀 더 많고 Tensor Core의 수 역시 576개로 2080 Ti의 544개보다 좀 더 많음
그에 비해 출고가는 2499달러로 출고가가 높아도 1199달러였던 2080 Ti를 고려하면 돌아버린 가성비를 보여줌
그나마 메리트가 있다면 VRAM인데 진짜 정직하게 2080Ti의 딱 두배임....
이런 이유 때문에 TITAN RTX는 사실 일반 소비자용으로는 구매하기 좋은 카드는 아님
성능은 분명 타이탄이 2080Ti 보다 높지만 가격을 고려하면 가성비가 너무 심각하게 구림
사실 타이탄 시리즈의 진정한 진가는 게이밍 용이 아니라 바로 딥러닝 같은 컴퓨팅용임
딥러닝은 그 특성상 거의 실시간 렌더링 수준으로 막대한 GPU 갈굼을 요구하고 학습 데이터의 물량으로 승부 보는 특성상
VRAM은 다다익선임. 때문에 이 TITAN RTX 자체도 일반 소비자들 입장에선 가성비 구린 그래픽 카드지만
사실 딥러닝 연구자의 입장으로서는 입문용으로는 가성비가 꽤 괜찮은 편에 속함.
근데 이것도 겉으로 보기에만 그럴 뿐이지 실상을 들여다보면 엔비디아의 경악할 만한 상술의 끝을 보여줌
딥러닝에서는 처리할 데이터 양이 굉장히 많기 때문에 보통은 그래픽 카드 한 장으로는 어림도 없고
그래픽 카드 여러 장을 꽂은 서버 여러대를 묶어서 분산 처리하는 경우가 대부분임
여기서 한 가지 문제점이 발생하는데 딥러닝 학습의 특성상 각 GPU(편의상 그래픽 카드 대신에 GPU라고 하겠음)에서 계산한 결과들을
모든 GPU가 공유를 해야하는데 이 공유해야 하는 데이터 양이 무지막지함
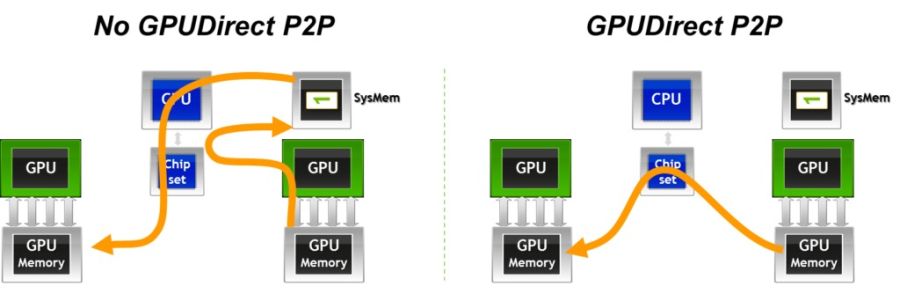
이걸 GPU 간의 P2P 통신이라고 하는데 일반적인 환경에서는 GPU끼리 서로 데이터를 주고받을 때,
위 그림의 왼쪽 부분처럼 버스를 통해 CPU까지 거쳤다가 다시 버스를 타서 다른 GPU로 데이터를 전송함
당연히 CPU에서 데이터 전송하는 걸 처리해야 하다보니 GPU의 빠른 속도가 CPU를 거쳐야 한다는 것 때문에 발목이 잡혀버림
쉽게 말해 CPU 때문에 병목 현상이 발생하는 것.
그래서 엔비디아에서 CPU를 거치지 않고 버스를 통해 GPU끼리 서로 직접적으로 통신할 수 있는 기술을 만들어서
열심히 기업하고 연구소에 팔아먹고 있음
문제는 GPU간 직접 통신 P2P 기술을 활용하기 위해선 그래픽 카드도 지원을 해야 하고 메인보드도 지원을 해야함
메인보드야 지원하는 거 아무거나 하나 사서 맞추면 되지만 문제는 그래픽 카드임
저 타이탄 RTX에는 저 기능이 없으요 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
그럼 어느 그래픽 카드에 저 기능이 있을까요?
 data-center-tesla-v100-pcie-625-ud@2x.jpg" alt="데이터센터 Tesla V100 PCle" />
data-center-tesla-v100-pcie-625-ud@2x.jpg" alt="데이터센터 Tesla V100 PCle" />
네 그렇습니다.
오늘의 주인공이신 Tesla V100에는 저 그래픽 카드 간 직접 통신 기능이 들어있으요 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
자 그럼 테슬라 V100 스펙 한 번 보고 가시겠습니다

CUDA 코어 5120개로 Titan RTX보단 확실히 많다
메모리도 GDDR5가 아니라 HBM2를 쓰고 대역폭도 900GB/s로 672GB/s인 Titan RTX보다는 확실히 좋음
VRAM도 최대 32GB까지 지원하고 무엇보다 중요한건 GPU간 직접 통신을 지원해서 여러 장의 GPU를 쓸 수록 연산 속도에 더 이득이라는 거죠!
자 그럼 테슬라 V100의 가격을 한 번 볼까요?


네 그렇습니다.
메모리 더 넣어주고(32GB 한정), 대역폭 1.5배 정도 늘려주고 CUDA 코어 개수 1000개 쯤 더 박아주고 GPU간 직접 통신 지원하니까
가격이 최소 3~4배나 뛰어버리는 기적의 현장
이게 엔비디아가 진짜 돈 버는 영역임
기업용, 연구용 그래픽 카드로는 진짜 악랄하게 돈 뜯어먹음
기능 하나 쬐끔 추가된 거 뿐인데 성능을 위해서라면 얘네에 돈을 질러야 함
진정한 독과점의 폐해란 바로 이런 것입니다 여러분....
근데 여기서 끝일 줄 알았죠?
설령 GPU랑 메인보드가 GPU간 직접 통신 기능을 지원해도 메인보드의 PCI-e 버스를 이용하는지라 데이터의 양이 더 많아지면
여기서도 병목 현상이 생길 수 있음
그래서 엔비디아가 NVLink라는 기술을 개발했음
대충 PCI-e 버스 쓰는 것보다 몇배는 더 빨라요! 라는게 핵심 내용.
근데 위에서 소개했던 테슬라 V100은 이 NVLink 못 쓰는 PCI-e 버스로만 P2P 통신을 하는 그래픽 카드임
네 그렇습니다 ㅋㅋㅋ NVLink 쓰려면 또 얘를 지원하는 그래픽 카드를 구매해야 하는 거임 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ

근데 카드만 팔고 끝낼 엔비디아가 아니지 ㅋㅋㅋ
메인보드도 만들어서 서버 형태로 못 팔건 없잖아?
그래서 엔당에서 DGX라고 해서 저렇게 Tesla V100 NVLink 그래픽 카드 8개 꽂은 서버를 출시함
근데 위에 기사 제목 보면 아시겠지만 저 그래픽 카드 8장 꽂힌게 가격이 1억 6천입니다 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
DGX-2라고 해서 GPU 16개 꽂힌 것도 있는데 얘는 그럼 얼마냐?
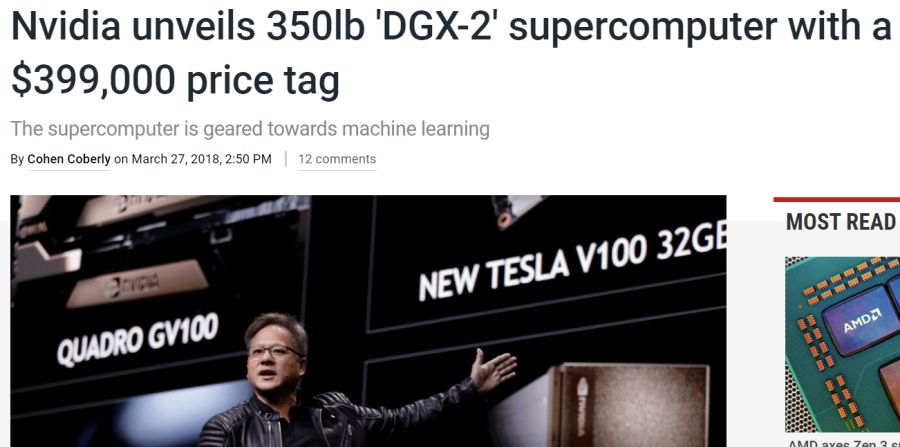

......
뭐 사실 요즘 대부분 기업들 추세가
B2B 거래에서 많이 남기고 B2C 에서는 친근한 이미지 용으로 싸게(?) 푸는거긴 하지만
진짜 요즘 엔비디아는 너무한거 같음
그리고 이건 개인적인 생각인데
요즘 4차 산업혁명이니 뭐니 하면서 얘기는 많이 나오는데
정작 다들 무슨 코인이니 알파고 지배설이니 엉뚱한 얘기만 하는거 같아 안타까움
4차 산업혁명이 나온지 얼마 안된 개념이기도 하고 애매모호하기도 해서 그런것 같은데
인공 지능 쪽에선 이런 식으로 데이터나 장비에 따른 자본의 격차에 따른 기술의 뒤쳐짐 같은건
잘 나오지 않는 거 같아 마음이 무겁습네다
자본 주의 사회에서 돈 많은 놈이 짱인건 당연한거지만
정작 이런 장비 싸움, 데이터 싸움에 대해서는 정부 관료들도 그렇고 생각보다 관심이 그렇게 다들 크지 않은 거 같음
사실 이런 쪽 지원이 되게 절실한 건데....
유머는 새벽에 잠 안자고 이런 뻘글 쓰고 있는 내 신세가 유머
루리웹-7202586835
라데온도 일단은 작업용 글카가 있다곤 하는데 쩌리인거 가터
그래서 그런가 일반 소비자용이랑 기업용랑은 아예 단위부터 다르더라고
정부돈이나 연구비 제대로 완창 따온거 아니면...대학교 연구소에서도 저런거 못쓰더라 ㅋㅋ
세상에
짜장면이최고야
어떻게 보면 엔비디아 진정한 밥줄이니 기를 쓰고 덤비겠지 기업이나 연구소 제외하면 그나마 제일 많이 팔수 있는 곳이 콘솔 쪽일텐데 여기는 이미 암드가 선점했으니...
짜장면이최고야
그게 어려운게 연구에 땡길수 있는 액수가 적어요 인텔처럼 방심하고 있지 않는한 어림없죠
암드가 이번 라이젠에 너무 많이 추진력을 소모해서 ㅠㅠ 당분간은 존버가 답
언젠가부터 엔비디아가 80번대에 풀칩을 안넣어주고 타이탄이라는 이름을 붙여서 풀칩을 미친듯한 가격에 팔듯이 기업용도 미친듯한 착취가 가면갈수록 이뤄지는구만.. 저정도 장비 쓰는사람들은 장비돌리는 시간도 돈이라서 ㄹㅇ 피눈물 흘리면서 다 사야겠지 ㄷㄷ
테슬라가 쿼드라쪽인건가? 웍스용 글카는 뭐 옛날부터 개ㅈㄹ이 심했으니.... 암드가 좀 분발해줬으면 좋겠다 진짜
쿼드로가 렌더링 같은 워크스테이션용이라면 테슬라는 인공지능 컴퓨팅 용 라인업인거 같음 일단 둘이 같은건 아님
아 그렇구만 테슬라는 인공지능, 쿼드라는 렌더링...... 엔당이 ai쪽으로 투자 미친듯이 해서 이 분야는 암당이 쫒을 수 없는 분얀가..... 안타깝구만
AI 쪽에서 글카 쓰는 소프트웨어는 거진 다 CUDA 쓴다고 봐도 됨 게다가 분산처리도 엔비디아 글카용 NCCL 같은 라이브러리까지 싹다 구현되어있으니 하드웨어도 울며 겨자먹기로 엔비디아쪽으로만....
삭제된 댓글입니다.
루리웹-3696799960
그게 또 참 애매한 것이 이게 처음 막 구축하려는 단계에선 서버 하나로는 연구실의 수요가 감당이 안됨 특히나 이것 저것 돌려본답시고 너도나도 GPU 여러개씩 쓰기 시작하면 최소한 인당 서버 3~4개는 있어야 하는데 그렇다고 저런 DGX 같은 거 막 들여놓을수도 없고 가성비 좀 좋은 글카로 서버 여러대를 맞추자니 속도가 노답이고... 진짜 애매함 ㄹㅇ루
루리웹-3696799960
테슬라는 그래픽 렌더링 기능이 없음다.
google TPU 가자~
TPU는 아마존 AWS 같이 대여해서 쓰는 방식이라 시간당 돈 받는데 딥러닝은 학습 오래 걸릴때는 몇 주씩 켜놓을 때도 많아서 저것도 비용 만만찮게 깨질거임 오히려 직접 서버 사서 구축하는것보다 비용 더 나올수도 있음 전기세+냉방비용도 포함한다면야 얘기가 다르겠지만
다들 생각하기에 4차산업이랑 인공지능은 별상관없다고 보니까? 핵심은 완전무인화 완전분배인데 약인공지능의 한계상 우리가 필요하는 완전무인의 필수요소인 강인공지능이 나오기 힘들다고 보고됬을테니까?
코카콜라x펩시
데이터 많이 쓰고 글카 여러장씩 써보면 체감됨.. 뭐 모델이나 데이터 양에 따라 다르겠지만..
코카콜라x펩시
몇백장 부럽다... 영상처리면 GPU활용률도 높을텐데 저거로 바꾸면 훨씬 더 빨라질듯 ㅋㅋㅋ
코카콜라x펩시
ㅗㅜㅑ 직접 다 하셨구나 ㄷㄷ 사실 뭐 이론상으론 느려도 돌릴수야 있으니까 문제되지는 않는데 기능 쫌 추가했다고 값이 배로 뛰는게 꼬와서 글 써봤음 ㅋㅋㅋ
코카콜라x펩시
의외네... 1080ti 가 p2p 된다고 해서 그걸로 테스트 해보시니까 P2P 지원되는 메인보드로 P2P 기능 썼을때 속도 30% 정도 올랐다고 했었음 뭐 자세한 환경은 모르니까... 타이탄 가성비 값인건 ㅇㅈ 근데 기능 쫌만 더 넣어주라....
코카콜라x펩시
ㅋㅋㅋㅋ 글카니까 ㄹㅇ루 전기먹는 하마 서버실 가면 머리는 에어컨 때문에 차가운데 서버 바람나오는 곳은 따뜻함 ㅋㅋ