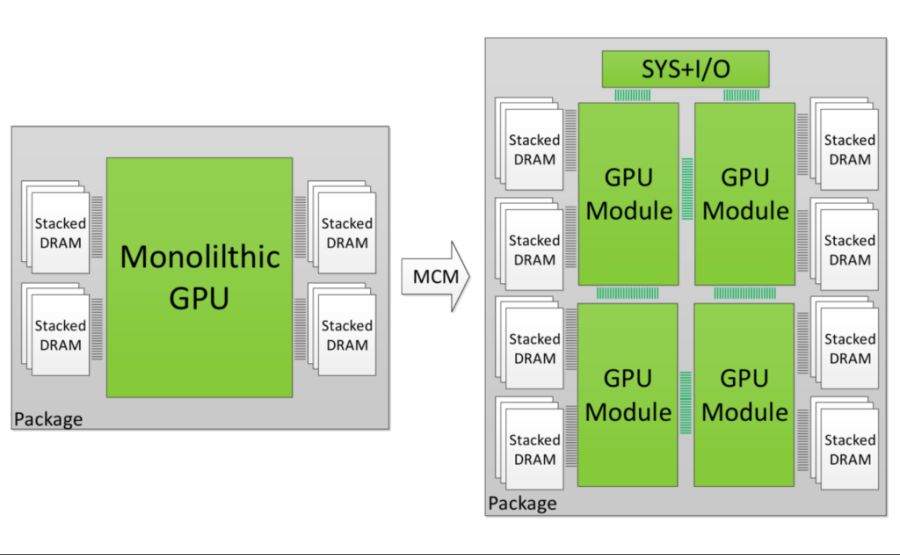
NVIDIA, 차세대 호퍼 그래픽 카드를 사용하여 MCM 디자인으로 전환할 수 있음 (AMD의 Ryzen Chiplet과 유사)
NVIDIA의 최고 경영자는 몇 년 전에 무어의 법은 죽었다고 주장했습니다
따라서 칩 소형화가 한계에 도달하기 시작했다는 사실은 놀라운 일이 아닙니다
인텔은 신경쓰지 않았으며 결과는 명확합니다
이 회사는 1,400만 개의 CPU가 부족한 상태에서 10nm 노드로 이동하기 위해 고군분투 하고 있습니다
AMD는 모놀리식 다이 대신 칩렛을 사용하여 MCM 설계로 마이그레이션 했으며
이는 Ryzen CPU의 성공에 크게 기여하여 소비자 공간에서 HEDT 수준의 성능을 가능하게 합니다
이제 NVIDIA는 차세대 설계에 멀티 칩 모듈 설계를 사용하여 AMD의 규칙 책에서 페이지를 넘겨받을 것 같습니다.
기사전문 https://quasarzone.co.kr/bbs/board.php?bo_table=qn_hardware&wr_id=342376
대충 하나의 큰 GPU를 쓰는 방식을 버리고 여러개의 작은 GPU를 모듈로 배치해서 서로 통신하게 하는 방식인듯. 칩 사이즈가 작아지니 수율이 상승해 단가가 줄어들고 발열문제도 완화시킬 수 있으므로 클럭도 올릴 수 있을 듯. 각 코어(스트리밍프로세서)가 서로 통신할 일이 많지 않은 GPU니까 충분히 시도해 볼 만한 방식이라 생각되긴 하는데, 업계에서 지금까지 이런 시도를 하다가 문제가 생긴 전례가 많기 때문에 좀 지켜봐야 할 듯.
하나의 커다란 칩을 쓰려면 그만큼 수율이 내려갑니다. 커다란 덩어리가 멀쩡한게 나와야 하니까요. 작은 칩의 조합으로 가면 싸게 만들 수 있습니다. 그게 amd 현재 cpu입니다. ccx라고 4코어단위 유닛 2개 조합으로 가고 6,4코어짜리는 불량감자들 조합으로 만듭니다. 저방식의 문제는 코어 간 통신을 해야할때 하나의 칩 단위에서 다른 칩 단위랑 통신할때 느려지는거고 그래서 게임에서 문제가 나는겁니다.
농담이 아니라 제목만 보고 MCM 디자이너 영입해서 외관 디자인하는줄 알았음..
GPU는 CPU랑 달리 극도로 병렬화된 프로세서라 물리적으로 떨어져 있는 것에 따른 디메리트가 CPU에 비하면 상대적으로 적습니다. 예전에는 PCIe를 거치면서 통신했기 때문에 비교적 속도가 느렸고 그만큼 양 GPU가 동기화하는데 있어 상대족으로 애로사항이 많았지만. 요즘엔 Nvlink나 인피니티 패브릭 같은 내부 인터페이스로 처리할테니 예전보단 낫지 않을까 싶어요.
[삭제된 댓글의 댓글입니다.]
데스윙 스트랜딩
대충 하나의 큰 GPU를 쓰는 방식을 버리고 여러개의 작은 GPU를 모듈로 배치해서 서로 통신하게 하는 방식인듯. 칩 사이즈가 작아지니 수율이 상승해 단가가 줄어들고 발열문제도 완화시킬 수 있으므로 클럭도 올릴 수 있을 듯. 각 코어(스트리밍프로세서)가 서로 통신할 일이 많지 않은 GPU니까 충분히 시도해 볼 만한 방식이라 생각되긴 하는데, 업계에서 지금까지 이런 시도를 하다가 문제가 생긴 전례가 많기 때문에 좀 지켜봐야 할 듯.
데스윙 스트랜딩
CPU나 GPU 뚜따하면 한가운데 직사각형 번쩍 거리는게 있는데 그게 반도체 칩임. 전엔 보통 한덩어리로 된 칩을 썼는데 이제 그걸 쪼개서 여러 덩어리로 나눈다는 이야기임. 이미 라이젠 등 일부 CPU나 GPU에서 쓰고 있는 방식임.
[삭제된 댓글의 댓글입니다.]
데스윙 스트랜딩
좋은 설명 감사합니다만.. 아직 이해가 안되는데 조금만더 쉽게 설명해줄수 있을까요?
루리웹 정보란
하나의 커다란 칩을 쓰려면 그만큼 수율이 내려갑니다. 커다란 덩어리가 멀쩡한게 나와야 하니까요. 작은 칩의 조합으로 가면 싸게 만들 수 있습니다. 그게 amd 현재 cpu입니다. ccx라고 4코어단위 유닛 2개 조합으로 가고 6,4코어짜리는 불량감자들 조합으로 만듭니다. 저방식의 문제는 코어 간 통신을 해야할때 하나의 칩 단위에서 다른 칩 단위랑 통신할때 느려지는거고 그래서 게임에서 문제가 나는겁니다.
주중미군
cpu는 그래야 할 일이 분명히 많은데 gpu는 그럴 일은 없어보이니 일리는 있어보이는데...그게 또 생각대로 안되는 경우도 있으니 봐야 알 듯.
CCX는 4코어끼리 1:1 크로스바 방식으로 직결해놓은 하나의 클러스터이지 그 자체로는 완성된 칩 내지는 다이가 아닙니다. 오히려 CCD가 님이 말하시는 것에 가깝죠.
다른 칩끼리 데이터 전송할 때 지연이 생기지 않으려나 라이젠도 ccx가 다르면 지연 생기는데
anotherW
GPU는 CPU랑 달리 극도로 병렬화된 프로세서라 물리적으로 떨어져 있는 것에 따른 디메리트가 CPU에 비하면 상대적으로 적습니다. 예전에는 PCIe를 거치면서 통신했기 때문에 비교적 속도가 느렸고 그만큼 양 GPU가 동기화하는데 있어 상대족으로 애로사항이 많았지만. 요즘엔 Nvlink나 인피니티 패브릭 같은 내부 인터페이스로 처리할테니 예전보단 낫지 않을까 싶어요.
그런데 roP의 병렬화를 ccx 분리와 동시에 진행시켜버리면 tcu랑 roP 사이에 직렬구조 충동에 의해서 다소 문제가 있지 않나 싶네요. 엔비디아가 왜 이런방향으로 가는지 이해는 가네요.
농담이 아니라 제목만 보고 MCM 디자이너 영입해서 외관 디자인하는줄 알았음..