
전문을 손수 번역할 능력이 안되서 구글 번역의 힘을 빌려서 올려봅니다
인텔은 어제 2018 년 아키텍쳐 데이 행사를 열었으며, 최고 경영진이 조만간 아키텍처와 제품 로드맵에 대한 방향을 계획하고있다. 이 행사는 로버트 노이스 (Robert Noyce)가 소유 한 집에서 열렸습니다. "실리콘 밸리 시장"으로 알려진 노이스 (Noyce)는 1968 년 고든 무어 (Gordon Moore)와 인텔을 공동 창립했다. 이 저택 설정은 인텔이 분석가와 언론인의 새로운 방향을 알리는 데 완벽한 배경이었습니다. 인텔은 10nm 공정의 CPU 제품 생산량의 지연 으로 인해 압박감을 느끼고 있지만, 소비자와 서버 시장에서 경쟁에서 우위를 차지할 수있는 몇 가지 트릭을 가지고있는 것으로 보인다.
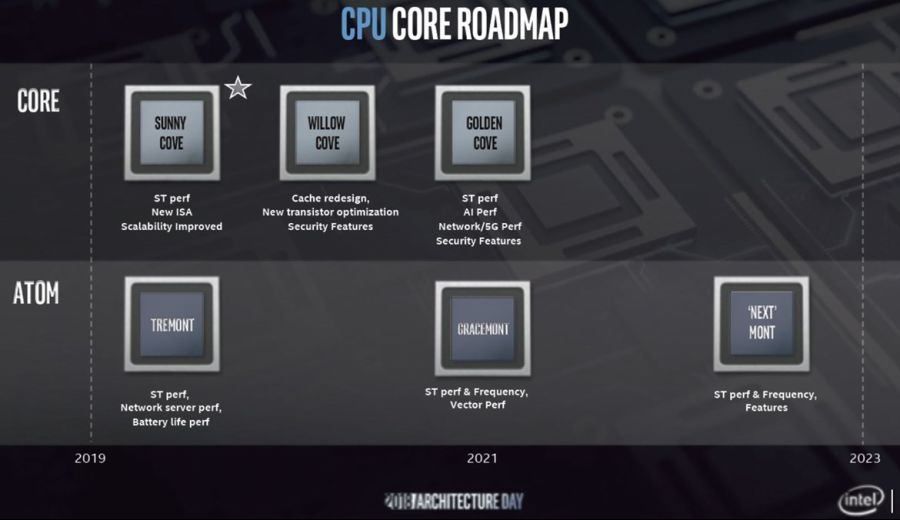
첫 번째는 Intel의 차세대 Core CPU 플랫폼 인 Sunny Cove입니다. 흥미롭게도 이것은 내부 코드 명에 대해 처음 들어 본 적이 있지만 이전 버전보다 "더 깊고 넓고 똑똑"하며 제온 (서버) 및 코어 (소비자) 프로세서의 기초를 형성 할 것입니다 인텔은 Sunny Cove가 인공 지능 (AI), 압축 처리 및 암호화 작업 부하를 가속화하기 위해 전용 레지스터 및 새로운 명령어 세트를 포함 할 것이라고 밝혔다. AES 및 SHA-NI 지침을 통해).

써니 코브 (Sunny Cove)는 인텔의 10nm 제조 공정을 기반으로하며, 14nm 공정으로 제작 된 여러 세대 제품을 환영한다. 전반적인 성능 향상에 매우 중요한 다른 개선 사항으로는 병렬 처리 증가, 버퍼, 명령어 및 데이터 캐시 크기 증가, 대기 시간 감소 및 분기 예측 정확도 개선 등이 있습니다. 아키텍처의 할당 단위는 4에서 5로 증가했으며 실행 포트는 8에서 10으로 증가했습니다 (Haswell은 이전에 포트 수를 6에서 8로 증가 시켰습니다). Sunny Cove는 클럭 사이클 당 2 개의로드 및 2 개의 스토어를 생성 할 수 있습니다 (이전 Gen 2로드 및 1 개 스토어 대비).
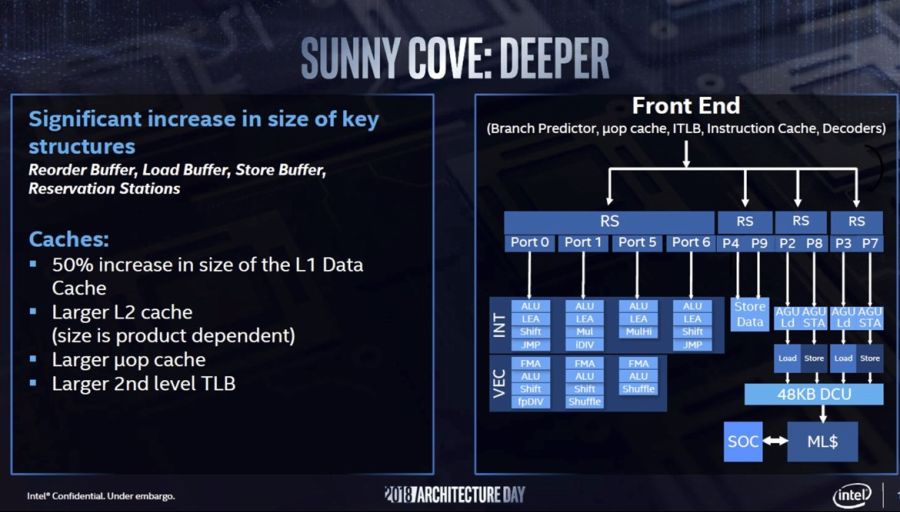
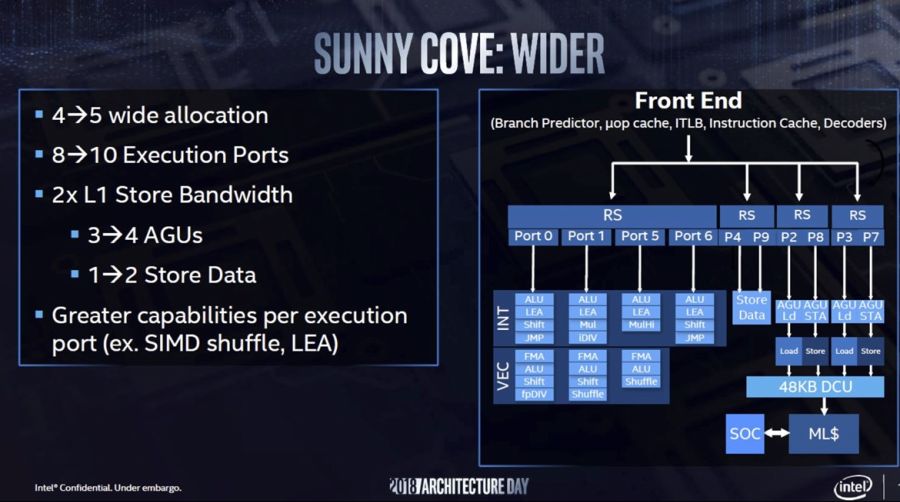
사물의 메모리 측면에서, 선형 주소 공간은 48 비트에서 57 비트로, 물리적 주소 공간은 52 비트로 증가했습니다. 예상대로, Sunny Cove는 Whisky Lake 및 Cascade Lake 에서 이미 구현 된 Meltdown 및 Spectre에 대한 하드웨어 수준의 완화를 특징으로하지만 향후의 공격을 방지하기 위해 아키텍처를 더욱 강화할 것입니다.
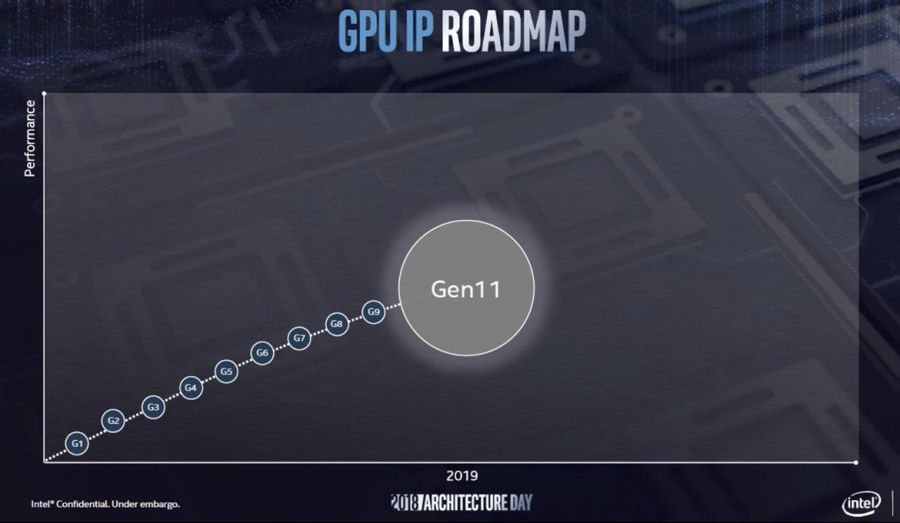
Sunny Cove를 보완하는 것은 Intel의 차세대 통합 그래픽 (Gen11)으로 2019 년에 출시 될 예정입니다. 기존 Gen9 그래픽과 비교하여 Gen11은 향상된 실행 단위 수를 24 개에서 64 개로 늘리면서 컴퓨팅 성능을 1 TFLOPS 이상으로 끌어 올렸습니다. 이 성능은 경쟁사의 개별 그래픽 솔루션에 비해 여전히 열악한 편이지만, 노트북에서 데스크톱에 이르기까지 통합 된 그래픽 성능에만 의존하는 시스템의 성능은 큰 도약입니다. 인텔은 분명히 게임 성능 향상 에 주력 하고 있으며, 최신 게임에 대한 업데이트, 성능 향상, 호환성 향상 및 Day 0 지원을 통해 드라이버 게임을 강화했습니다.
또한 Intel Gen11 그래픽은 타일 기반 렌더링은 물론 적응 형 동기화 기술을 지원하여 AMD FreeSync 및 NVIDIA G-Sync에 유사한 눈물 및 지터가없는 게임 경험을 제공합니다. 특히 프레임 속도가 연결된 패널의 새로 고침 빈도. 좋은 소식은 인텔의 적응 형 동기화 기술이 외부 하드웨어를 필요로하지 않으며 발생 및 가동되지 않으며 AMD Freesync 모니터와 호환된다는 것입니다. 요즘 시장에 나와있는 저가의 FreeSync 지원 패널이 풍부 해 졌다고 생각하면 NVIDIA는 독점적 인 G-Sync 솔루션으로 추위에 빠질 수 있습니다.


흥미롭게도, Gen11 EU (실행 단위)는 Gen9 EU의 실리콘 영역의 약 75 %만을 차지하는 것으로 나타났습니다. 그러나 2 배가 넘는 그래픽을 사용하여 Gen11은 상당한 성능 향상 효과를 얻을 수 있습니다. 인텔은 인텔 써니 코브에서 Gen11 그래픽과 Gen9 커피 레이크 기반의 머신으로 Tekken 7을 시연하고 있었고 프레임 속도가 크게 향상되었습니다. 특별히 확정되지는 않았지만, EU 계산에 대해 계산하면 이전 인텔 IGP와 비교했을 때 성능이 최소 2 배 이상 향상 될 것으로 예상 할 수 있습니다. 인텔은 이와 유사한 전력 범위에 있음을 확인했습니다.

또한 Gen11의보다 효율적인 EU는 AI 작업 부하 처리 개선을 위해 향상된 FPU 처리량과 함께 향상된 정밀 혼합 성능 (Int8 및 Int16)은 물론 고성능 및보다 효율적인 HEVC 비디오 디코딩을위한 Intel VPU 미디어 엔진의 향상된 기능을 제공합니다 하드웨어로 인코딩 할 수 있습니다.

또 다른 흥미로운 점은 인텔의 새로운 GPU 아키텍처는 인텔이 "거친 픽셀 쉐이딩 (Coarse Pixel Shading)"이라고 부르는 것을 통해 미래 지향적 인 기능을 보유하고 있다는 점이다. 이것은 NVIDIA의 GeForce RTX 아키텍처 에서 생각할 수있는 개념입니다. GPU가 복잡성과 작업 부하에 따라 다양하고 효율적인 적응 픽셀 쉐이딩 기법을 수행하고, 세부 사항이 필요한 씬의 음영 영역은 보이지 않거나 흐려지지 않는 영역은 덜 수신합니다 쉐이더 처리가 필요하므로 오버 헤드가 낮아집니다.
마지막으로, 신비한 인텔 이산 GPU와 GPU 공간에서의 인텔의 높은 수준 전략 의 미래를 한눈에 바라 보는 사람들을 위해, 위 슬라이드는 회사가 어디로 향하고 있는지에 대한 확실한 그림을 제공합니다. 인텔의 Xe GPU 제품 이니셔티브의 확장 성 메시징은 모두 동일한 아키텍처를 기반으로하는 "테라 플롭스에서 페타 플롭스로"라는 확실한 고결한 메시지입니다. Intel의 10nm 공정이 Sunny Cove CPU 코어 아키텍처와 함께 궤도에 서고 살아있는 것처럼 보입니다. 또한 회사가 주요 그래픽 침투를 목표로하는 큰 총을 가지고 있다고 생각하면 동일한 IP를 사용하는 모든 컴퓨팅 플랫폼에서 Chipzilla가 2019 년 이후에 도전장을 던질 의사가 있다고 말할 수 있습니다.
서니 코브라는 거창한 아키텍처명을 들고 왔지만 본질적으로는 우리가 이제까지 '아이스레이크'로 알고 있었던 녀석입니다. 스카이레이크X 시리즈를 '베이신 폴'로 칭하던 것과 비슷함. 프론트엔드 확장이나 AVX512 지원이야 이미 한참 전부터 예고되었던 것이라 이 역시 완전히 새로운 내용은 아닙니다.
그리고 1테라플롭스를 찍었다...고 해 놨는데 이게 FP16 기준인지, FP32 기준인지를 모르겠네요. FP16 기준이면 아직도 폐급인거고 FP32 기준이면 이제 간신히 레이븐 릿지의 그것을 넘은 건데 내년 말에나 나올 10nm로(현재 TSMC의 7nm랑 비슷한 성능) 2015년에 나온 1세대 14nm보다도 구려터진 GF의 14nm로 뽑은 레이븐 릿지를 간신히 상대하는 수준이라면 이 역시 고개가 가우뚱할만한 소식.
음? 코두리 효과는 11세대부터 아닌가요??
드디어 10나노냐 빌어먹을놈들...
[삭제된 댓글의 댓글입니다.]
루리웹-4982537509
음? 코두리 효과는 11세대부터 아닌가요??
얘는 새 아키텍처니 멜트다운 안 생기겠죠?
예상대로, Sunny Cove는 Whisky Lake 및 Cascade Lake 에서 이미 구현 된 Meltdown 및 Spectre에 대한 하드웨어 수준의 완화를 특징으로하지만 향후의 공격을 방지하기 위해 아키텍처를 더욱 강화할 것입니다.
캐스캐이드 레이크에서 다 해결 했고 이후에 위해 아키텍쳐 레벨에서의 보안을 더 강화한다고 합니다
루리웹-4982537509
그럼 가격이랑 성능 나오는거 보면 되겠네요. 암드가 요새 잘 나가니 인텔도 분발해야할 듯 멍청한 CEO도 잘려나갔으니 좋은 제품들로 경쟁구도 나왔으면 좋겠네요.
그래서 철권 그래픽 옵션은 뭘로 줬대요?
드디어 10나노냐 빌어먹을놈들...
오호
철권는 프레임60고정일텐데...?
그래 정신좀 차리자 이제. 잘할수 있는 기업이 삽질하는거보면 진짜 안타까움
인텔 10나노야 왜 이제 나오냐?
마소 윈도우랑 애플 아이폰은 9를 버리고 인텔은 10을 버렸네요
서니 코브라는 거창한 아키텍처명을 들고 왔지만 본질적으로는 우리가 이제까지 '아이스레이크'로 알고 있었던 녀석입니다. 스카이레이크X 시리즈를 '베이신 폴'로 칭하던 것과 비슷함. 프론트엔드 확장이나 AVX512 지원이야 이미 한참 전부터 예고되었던 것이라 이 역시 완전히 새로운 내용은 아닙니다.
그리고 1테라플롭스를 찍었다...고 해 놨는데 이게 FP16 기준인지, FP32 기준인지를 모르겠네요. FP16 기준이면 아직도 폐급인거고 FP32 기준이면 이제 간신히 레이븐 릿지의 그것을 넘은 건데 내년 말에나 나올 10nm로(현재 TSMC의 7nm랑 비슷한 성능) 2015년에 나온 1세대 14nm보다도 구려터진 GF의 14nm로 뽑은 레이븐 릿지를 간신히 상대하는 수준이라면 이 역시 고개가 가우뚱할만한 소식.
단순히 FLOPS수치만 따질꺼면 Iris Pro 580에서 이미 FP32기준으로 1TFlops는 넘었습니다. 다만 실성능은 안습한 수준이지만요 쓰로틀링 때문인지는 모르겠지만 최근에 나온 커피레이크U에 들어간 Iris plus 655가 48 EU에 EDRAM 크기도 반토막임에도 불구하고 3D마크 점수는 더 높게 나옵니다. 근데 EU 개수가 24 -> 64로 늘었다고 표현한걸 보면 일반적인 데스크탑 CPU 기준으로 말한듯 한데 Iris가 아닌 일반형 제품에도 64EU를 넣어준다고 하면 그나마 저가형 라인업에서는 쓸만하지 않을까 합니다. 물론 EDRAM은 안들어갈테니 실성능은 레이븐릿지보다는 훨씬 떨어지겠지만요
사람내보내지 않고 외계인 갈아먹지 않았으면 자체 7나노까지도 가능했을텐데
아니 게임 시연을 해도 왜 프레임 고정인 철권으로 시연을 하지 어이없음