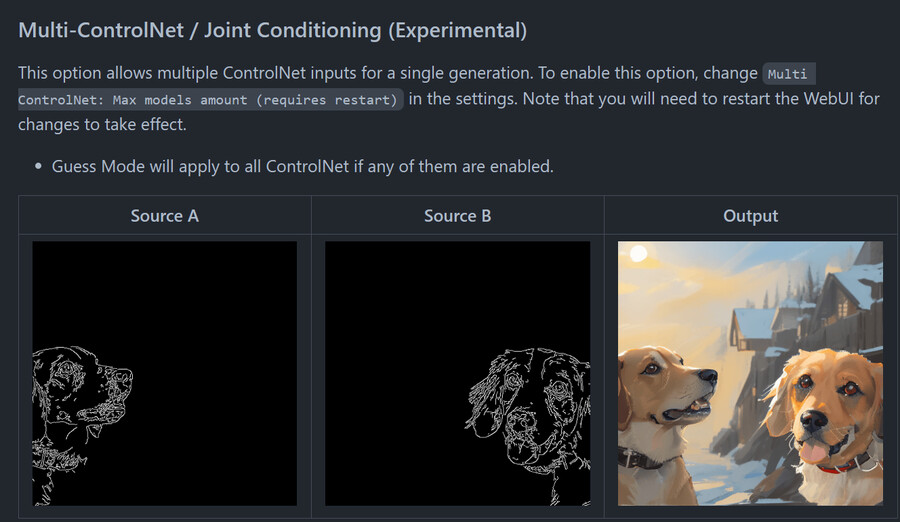
멀티 컨트롤넷은 말 그대로 여러개의 컨트롤넷을 동시에 사용할 수 있도록 하는 기능으로 예를 들면 뎁스와 포즈를 동시에 입력하는 것이 가능합니다.
사용법은 다음과 같습니다.
1. 설정의 ControlNet 탭에 있는 ControlNet: Max models amount (requires restart)를 1 이상으로 설정합니다.
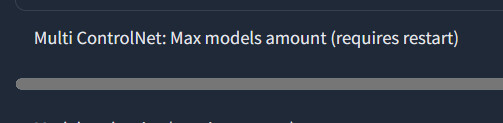
해당 기능은 2개 이상의 컨트롤넷 모델을 동시에 사용하기 때문에 Vram 소모가 1개보다 많으니 주의하시기 바랍니다.
2. 설정을 저장하고 Webui를 재시작하면 아래 이미지처럼 지정한 숫자만큼의 컨트롤넷 탭이 표시됩니다.
나머지 사용법은 일반적인 컨트롤넷과 동일합니다.
먼저 아래와 같은 오픈포즈 뼈대 이미지와 뎁스 이미지를 동시에 입력합니다.
멀티 컨트롤넷은 입력된 포즈와 뎁스 중에서 무엇이 앞에 있고 뒤에 있는지 인식하지 못 하기 때문에 구성이 전혀 다른 이미지(포즈, 뎁스)를 동시에 넣으면 이상하게 뒤섞인 이미지가 생성될 확률이 높습니다.
오픈포즈 뼈대 / 뎁스 이미지 / 결과

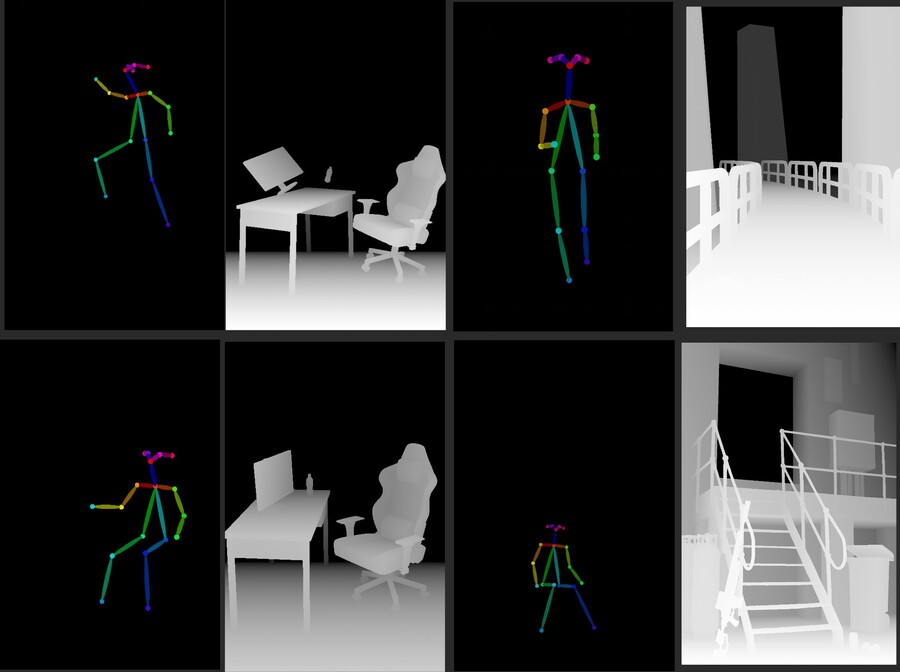
이런 경우에는 Guidance strength나 weight를 조정할 필요가 있습니다.
배경처럼 뒤로 오는 이미지의 강도를 낮추는 것이 원하는 장면을 생성하는데 도움이 됩니다.
그냥 입력했을 때와 배경의 강도를 낮추었을 때의 차이는 아래 이미지와 같습니다.

멀티 컨트롤넷을 100프로 활용하려면 입력되는 이미지들을 정렬할 필요가 있습니다.
이번에는 오픈포즈와 Seg를 동시에 사용해보도록 하겠습니다.
오픈포즈 뼈대로 자세를 잡고 Seg이미지에는 동일한 부위에 인간을 의미하는 보라색을 칠해줍니다.
결과는 아래 이미지와 같습니다.
오픈포즈 뼈대 / Seg 이미지 / 결과물
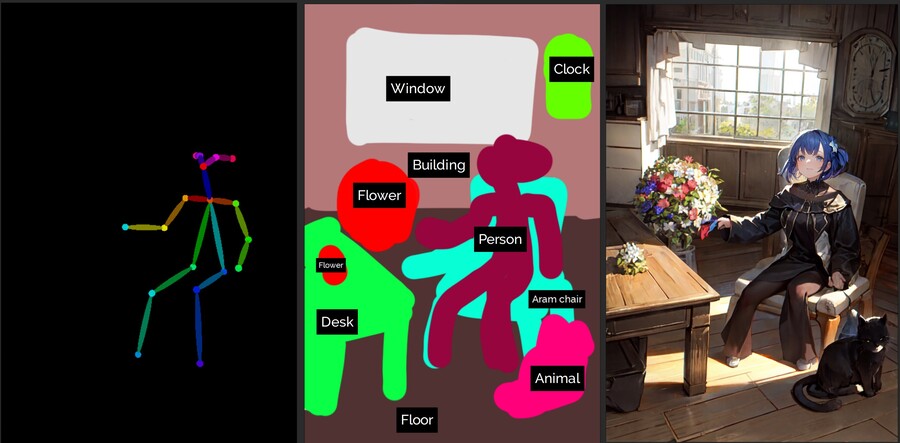

포즈와 seg의 위치가 정렬되어 의도했던 이미지를 생성하고 있는 것을 확인할 수 있습니다.
Seg는 정해진 색상에 매칭되는 대상을 원하는 위치에 배치하는 것이 가능하지만 포즈 같은 디테일이 랜덤하게 생성되고, 오픈포즈의 경우 반대로 포즈는 확실하지만 나머지가 랜덤하게 생성됩니다.
멀티 컨트롤넷을 사용하면 이러한 장점들을 합치는 것이 가능합니다.
Seg만 사용 / 오픈포즈만 사용 / Seg + 오픈포즈

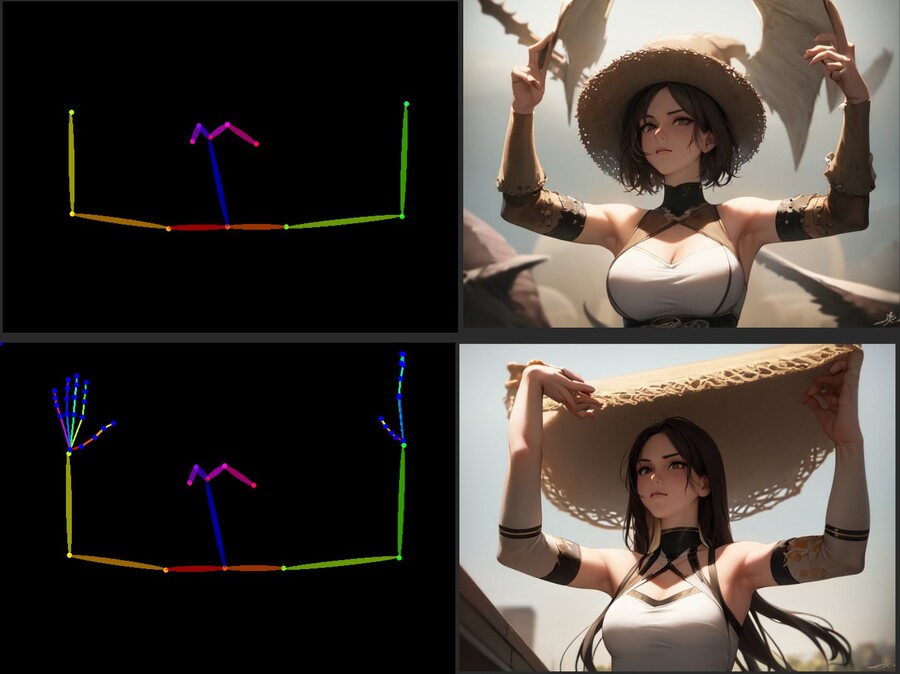
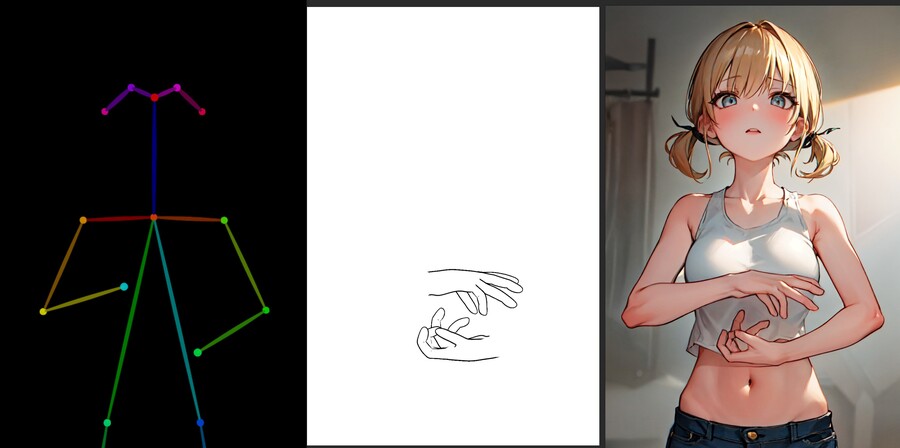
오픈포즈 모델은 손가락이 없는 뼈대 이미지를 사용해서 학습되었기 때문에 손가락을 넣어도 인식하지 못합니다.
오픈포즈 뼈대에 손가락을 추가하면 아래 이미지 같이 그냥 이상한 덩어리가 생성되는 경우가 대부분입니다.
뎁스 모델을 사용하면 손가락을 비교적 정확하게 생성하는 것이 가능하지만 입력된 이미지와 그로부터 나온 뎁스 이미지와 비슷한 형태의 이미지만 생성할 수 있다는 한계가 있습니다.

이제 멀티 컨트롤넷을 사용하면 오픈포즈의 포즈와 뎁스의 손가락 정밀성을 합쳐봅시다.
우리가 필요한 것은 손가락의 뎁스 이미지뿐이니 오픈포즈 뼈대에 손 메시를 추가해줍니다.
해당 블렌더 파일은 여기서 받으실 수 있습니다 : Character bones that look like Openpose for blender _ Ver_3.5 Depth+Canny (gumroad.com)
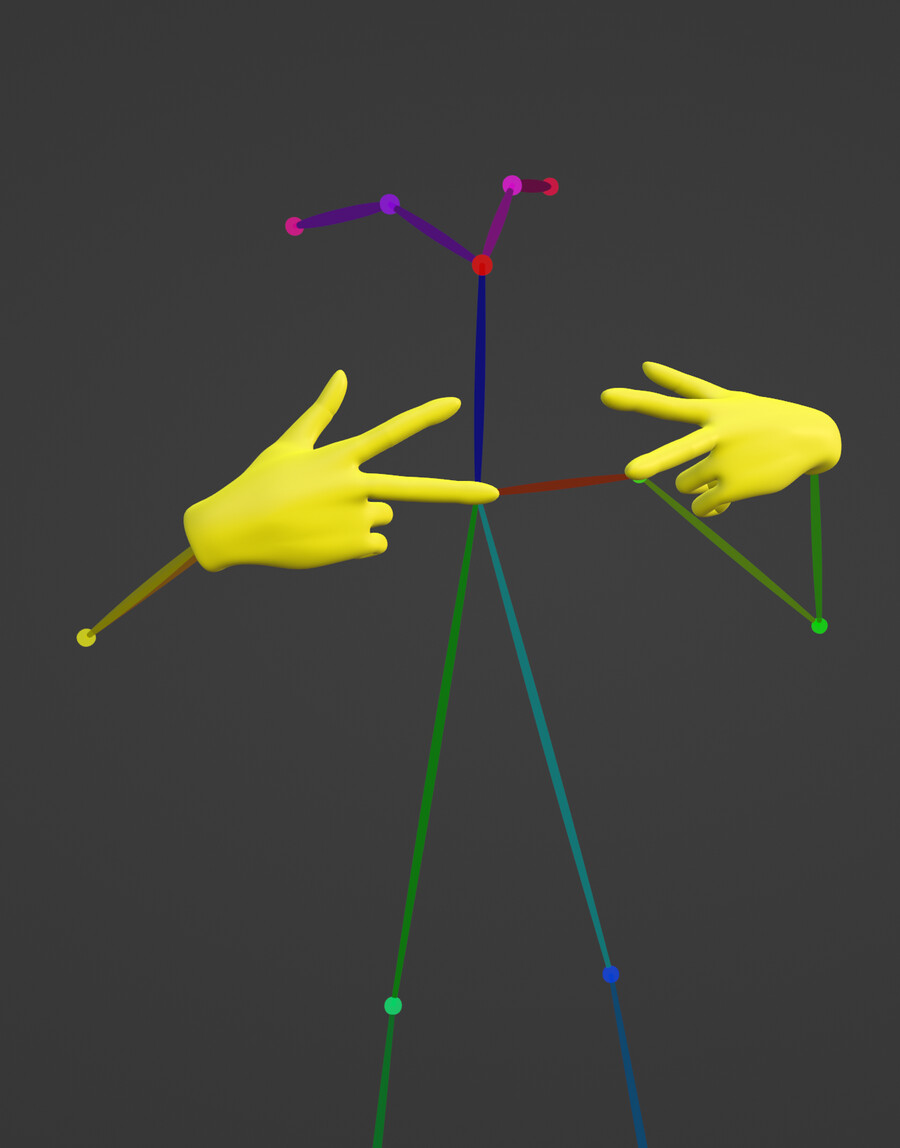
손 모델 뎁스와 오픈포즈 이미지를 별도로 렌더링하고 멀티 컨트롤넷에 각각 입력하면 아래와 같이 보다 정확한 손가락 이미지를 얻을 수 있습니다.
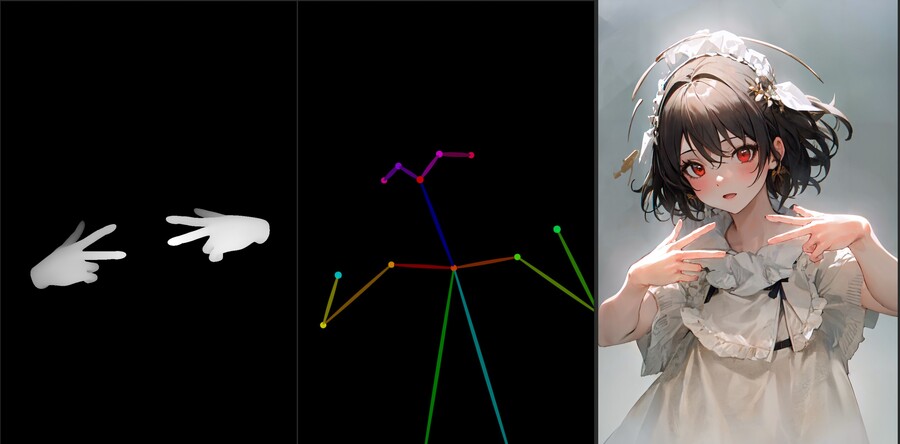

뎁스 모델의 weight를 올리면 꽤 복잡한 손가락 포즈도 가능합니다.
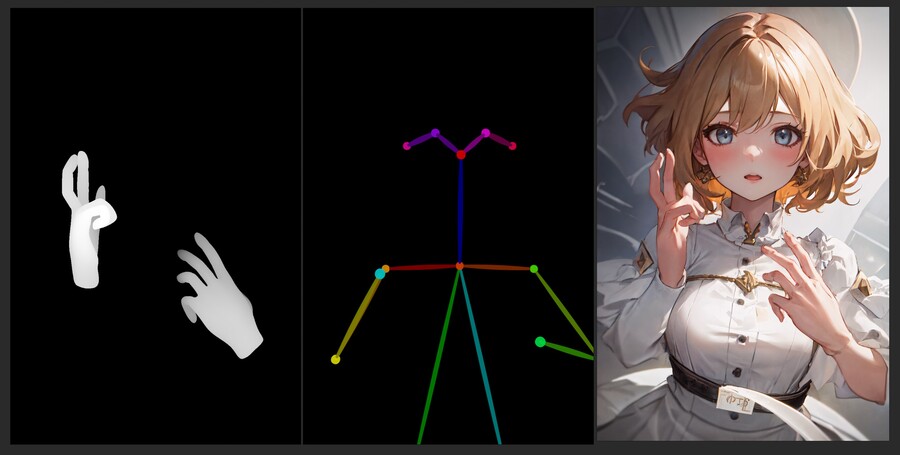



하지만 아래 이미지처럼 구분이 명확하지 않은 손가락 포즈는 부분적으로 뭉게져서 나올 확률이 높습니다.
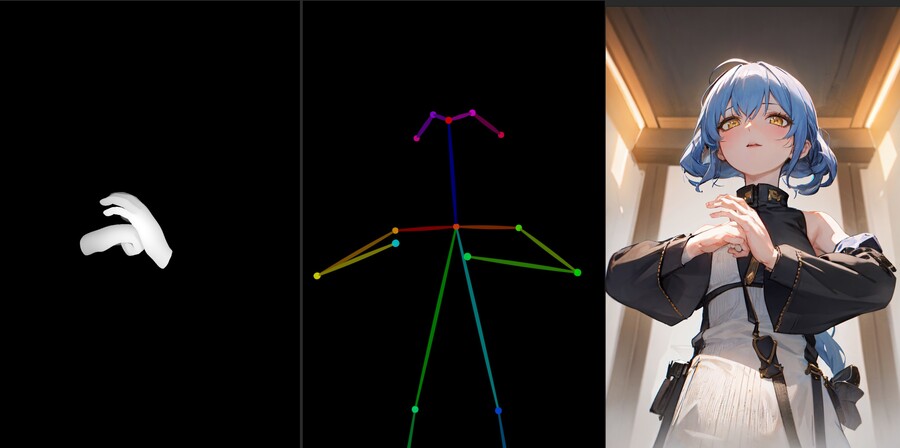

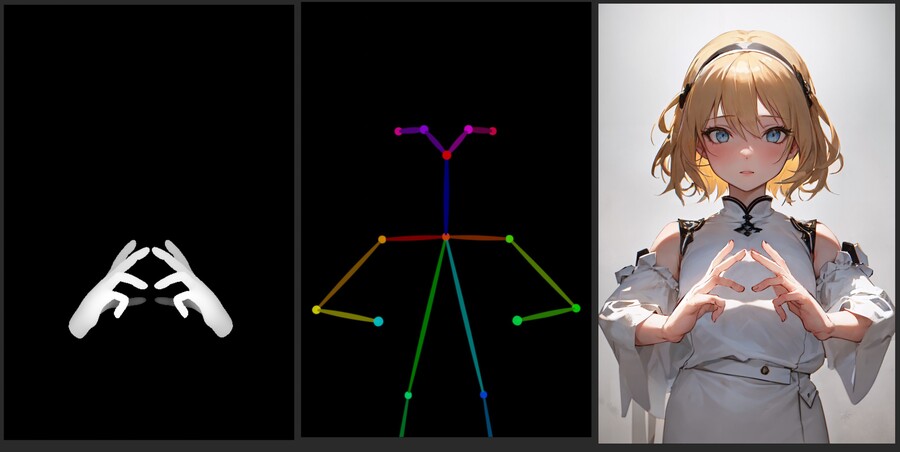

물론 뎁스 이외의 모델로도 가능합니다.
개인적인 테스트로는 손가락 포즈를 지정하는데는 Depth와 Canny가 가장 효과적이었습니다.

Canny와 오픈포즈를 사용해서 생성한 손가락 포즈 이미지들은 아래와 같습니다.





유게에서 보기 드문 논문 같은 유익한 글…
AI그림이 코딩하는것과 비슷한거보니 코딩해주는 AI와 합쳐지면 더 무서워지겠네...
git이 제대로 환경변수에 입력되지 않았나봐요 chatGPT에게 에러코드 복사해서 붙여줬더니 알려주네요 ai그림 배우려고 ai한테 질문하고 ㅎㅎ 진짜 이런거라도 안배우면 조만간 어찌될지 끔찍하네요
와 선생님 정리해주시는거 항상 너무 이해하기 편해서 감탄합니다
유게에서 보기 드문 논문 같은 유익한 글…
AI그림이 코딩하는것과 비슷한거보니 코딩해주는 AI와 합쳐지면 더 무서워지겠네...
뭔가 인공지능이 딥러닝하는 방법을 본거 같다.
Ai강좌 ㅇㄷ
너무 갑작스런 발전에 정신을 못차리는 중
유입이라 아직 쪽지가 안되네요 제가 lora로 바로 이미지도 뽑을수 있는줄알고 13번부터 했다가 걍 딥러닝만 되길래 다시 1번으로 돌아가서 webui를 했습니다 근데 이미 한번 러닝쪽으로 돌려놔서 그런지 아니면 버전업들이 많이되면서 꼬인건지 webui_user.bat 이걸로 실행하면 에러뜨면서 진행이 안되는데 1번말고 다시 시작할 수 있는 강좌나 아니면 새로운 방법 있을까요?
루리웹-6289004982
git이 제대로 환경변수에 입력되지 않았나봐요 chatGPT에게 에러코드 복사해서 붙여줬더니 알려주네요 ai그림 배우려고 ai한테 질문하고 ㅎㅎ 진짜 이런거라도 안배우면 조만간 어찌될지 끔찍하네요
혹시 2D 그림 생성시 일관성이 거의 유지되기 어려운 문제에 대해서 무언가 논의되고 있는 기술적 해결책이 있을까요? 당장의 AI 그림생성 기술은 일러스트 하나를 만드는데엔 유용하지만 수십장, 넘어서서 수백화는 이어나갈 지속적인 매체에 등장할 다수의 캐릭터를 구현하는데엔 상당히 애로사항이 많은 것 같습니다. 캐릭터야 어느정도 LoRA로 해결한다 하더라도, 배경은 매번 생성시마다 달라지게 될텐데 아직까진 실용하는데에 어려움이 많지 않나 싶어서 해결책을 찾고 있었습니다. 또한, 사실 캐릭터들마다 LoRA 만들어서 해결하는것도 그다지 해결책이라고 보긴 어려운것같아서... 고민이 되어서 여쭙습니다. 직접 원하는 패션을 지시해서 구현한 복장이라면 일관성이 더 유지되지 못하고 계속 바뀌는게 참 어려움이 많네요... 캐릭터 학습 문제는 아직 개발중이라던 E4T (Encoder-based Domain Tuning for Fast Personalization of Text-to-Image Models)라는걸 사용하면 다수의 캐릭터를 쉽고 빠르게 학습시켜서 일관성있게 써먹을 수도 있지 않을까 싶은 기대감은 있는데, 그게 무료로 나올지 유료로 나올지도 모르겠고 일관성 면에서 얼마나 위력적일지도 모르겠습니다. 그동안 연재해주신 AI 관련 글들 하나도 빠짐없이 정독하고 이걸로 AI 그림생성에 입문한 아마추어입니다. 선생님 그동안 글 정말 잘봤고 진짜 놀라울정도로 잘 정리되었으며 유익한 글들 써주셔서 정말 감사합니다. 여러모로 많이 연습해보기도 하고 해외 디스코드 및 레딧 등도 뒤져가며 기술발전을 쫓아가느라 정신없으면서도 재미있습니다.
현재로서는 드림부스나 로라를 사용해서 캐릭터를 학습하고 img2img를 사용하는게 가장 확실한 방법입니다. 아래 트위터에 올라온 영상의 경우 봇치더락의 주인공 봇치를 학습시킨 드림부스 모델과 파츠를 seg 칼라로 분리한 3D 모델을 사용해 제작된 것으로 높은 일관성을 보여줍니다. https://twitter.com/TDS_95514874/status/1626817468839911426
비디오에 사용되는 일관성을 위한 기술이 개별 이미지들을 한장씩 뽑아내서 만화같은걸 만드는 경우에도 적용이 될 수 있나요? 아니면 여기엔 다른 기술이 필요한가요?
충분히 만화 만드는데 쓰일 수 있지 않을까요? 저도 웹툰을 이걸로 작업해보려고 합니다. 아직 배경을 어떻게 처리해야 하는 지에 대해서는 고민이 좀 더 필요할 수 있을 거 같아요.
동영상을 만들 수 있으면 당연히 만화도 가능합니다. 배경의 경우 캐릭터와 배경을 한번에 생성하기보다는 배경따로 캐릭터 따로 생성한 다음 포토샵 등으로 합치고, 약한 강도의 img2img로 다시 처리하는게 가장 깔끔합니다.
답변 감사합니다! 역시 포토샵, 블렌더의 응용은 필수인것같습니다
혹시 외주 관련해서 문의드리고 싶은데, 쪽지로도 전달 드렸지만 덧글로도 달아봅니다!
남의 그림들 배껴다 가지고 놀고 모자라 그 방법까지 공유하니깐 재밌어요?