http://semiaccurate.com/2013/01/02/xbox-next720-silicon-production-day-arrives/#.UORC9zWoGv0
2013년 1월 2일 테크놀로지 관련 사이트 SemiAccurate는 차세대 엑스박스의 oban 프로세서 (SOC) 양산 소식을 알립니다.
2012년 12월 31일 월요일부터 부터 양산이 시작되었습니다.
2013년 1월 21일 이후 상세 하드웨어 스펙 관련 내용 다량 유출
현재까지 알려진 유출된 내용 종합 정리
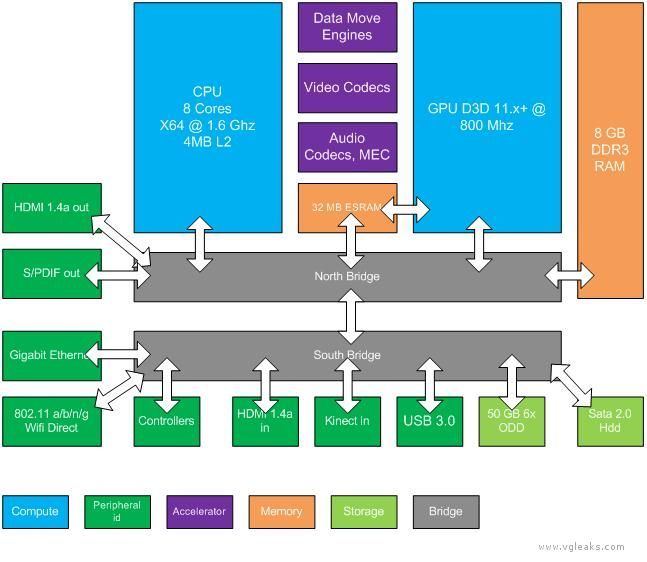
CPU:
- x64 Architecture
- 8 CPU cores running at 1.6 gigahertz (GHz)
- each CPU thread has its own 32 KB L1 instruction cache and 32 KB L1 data cache
- each module of four CPU cores has a 2 MB L2 cache resulting in a total of 4 MB of L2 cache
- each core has one fully independent hardware thread with no shared execution resources
- each hardware thread can issue two instructions per clock
GPU:
- custom D3D11.1 class 800-MHz graphics processor
- 12 shader cores providing a total of 768 threads
- each thread can perform one scalar multiplication and addition operation (MADD) per clock cycle
- at peak performance, the GPU can effectively issue 1.2 trillion floating-point operations per second
High-fidelity Natural User Interface (NUI) sensor is always present
Storage and Memory:
- 8 gigabyte (GB) of RAM DDR3 (68 GB/s)
- 32 MB of fast embedded SRAM (ESRAM) (102 GB/s)
- from the GPU’s perspective the bandwidths of system memory and ESRAM are parallel providing combined peak bandwidth of 170 GB/sec.
- Hard drive is always present
- 50 GB 6x Blu-ray Disc drive
Networking:
- Gigabit Ethernet
- Wi-Fi and Wi-Fi Direct
Hardware Accelerators:
- Move engines
- Image, video, and audio codecs
- Kinect multichannel echo cancellation (MEC) hardware
- Cryptography engines for encryption and decryption, and hashing
|
Stat |
Value |
|
|
Clock rate |
800 MHz |
|
|
Compute |
||
|
Shader cores |
12 |
|
|
Instruction issue rate |
12 SCs * 4 SIMDs * 16 threads/clock = 768 ops/clock |
|
|
FLOPs |
768 ops/clock * (1 mul 1 add) * 800 MHz = 1.2 TFLOPS |
|
|
Interpolation |
( 768 ops/clock / 2 ops ) * 800 MHz = 307.2 Gfloat/sec |
|
|
Geometry |
||
|
Triangle rate |
2 tri/clock * 800 MHz = 1.6 Gtri/sec |
|
|
Vertex rate |
2 vert/clock * 800 MHz = 1.6 Gvert/sec |
|
|
Vertex/buffer fetch rate (4 bytes) |
4 elements/clock * 12 SCs * 800 MHz = 38.4 Gelement/sec |
|
|
Vertex/Buffer data rate from cache |
38.4 Gelements/sec * 4 bytes = 153.6 GB/sec |
|
|
Memory |
||
|
Peak throughput from main RAM |
68 GB/sec |
|
|
Peak throughput from ESRAM |
128 bytes/clock * 800 MHz = 102.4 GB/sec |
|
|
ESRAM size |
32 MB |
|
|
GSM size |
64 KB |
|
|
LSM size |
12 SCs * 64 KB = 768 KB |
|
|
L2 cache size |
4 x 128 KB = 512 KB (shared) |
|
|
Texture |
||
|
Bilinear fetch rate (4 bytes) |
4 fetches/clock * 12 SCs * 800 MHz = 38.4 Gtexels/sec |
|
|
Bilinear data rate from cache |
38.4 Gtexels/sec * 4 bytes = 153.6 GB/sec |
|
|
L1 cache size |
16 KB/SC * 12 SCs = 192 KB (nonshared) |
|
|
Output |
||
|
Color/depth blocks |
4 |
|
|
Pixel clear rate |
1 8×8 tile/clock * 4 DBs * 800 MHz = 204.8 Gpixel/sec |
|
|
Pixel hierarchical Z cull rate |
1 8×8 tile/clock * 4 DBs * 800 MHz = 204.8 Gpixel/sec |
|
|
Sample Z cull rate |
16 /clock * 4 DBs * 800 MHz = 51.2 Gsample/sec |
|
|
Pixel emit rate |
4 /clock * 4 DBs * 800 MHz = 12.8 Gpixel/sec |
|
|
Pixel resolve rate |
4 /clock * 4 DBs * 800 MHz = 12.8 Gpixel/sec |
|
Virtual Addressing
All GPU memory accesses on Durango use virtual addresses, and therefore pass through a translation table before being resolved to physical addresses. This layer of indirection solves the problem of resource memory fragmentation in hardware—a single resource can now occupy several noncontiguous pages of physical memory without penalty.
Virtual addresses can target pages in main RAM or ESRAM, or can be unmapped. Shader reads and writes to unmapped pages return well-defined results, including optional error codes, rather than crashing the GPU. This facility is important for support of tiled resources, which are only partially resident in physical memory
ESRAM
Durango has no video memory (VRAM) in the traditional sense, but the GPU does contain 32 MB of fast embedded SRAM (ESRAM). ESRAM on Durango is free from many of the restrictions that affect EDRAM on Xbox 360. Durango supports the following scenarios:
- Texturing from ESRAM
- Rendering to surfaces in main RAM
- Read back from render targets without performing a resolve (in certain cases)
The difference in throughput between ESRAM and main RAM is moderate: 102.4 GB/sec versus 68 GB/sec. The advantages of ESRAM are lower latency and lack of contention from other memory clients—for instance the CPU, I/O, and display output. Low latency is particularly important for sustaining peak performance of the color blocks (CBs) and depth blocks (DBs).
Local Shared Memory and Global Shared Memory
Each shader core of the Durango GPU contains a 64-KB buffer of local shared memory (LSM). The LSM supplies scratch space for compute shader threadgroups. The LSM is also used implicitly for various purposes. The shader compiler can choose to allocate temporary arrays there, spill data from registers, or cache data that arrives from external memory. The LSM facilitates passing data from one pipeline stage to another (interpolants, patch control points, tessellation factors, stream out, etc.). In some cases, this usage implies that successive pipeline stages are restricted to run on the same SC.
The GPU also contains a single 64-KB buffer of global shared memory (GSM). The GSM contains temporary data referenced by an entire draw call. It is also used implicitly to enforce synchronization barriers, and to properly order accesses to Direct3D 11 append and consume buffers. The GSM is capable of acting as a destination for shader export, so the driver can choose to locate small render targets there for efficiency.
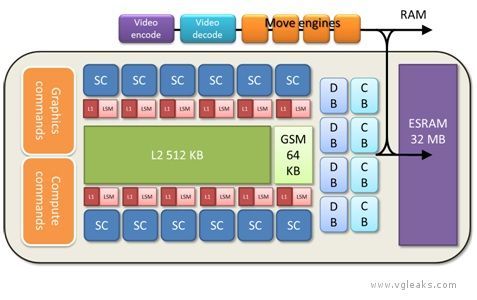
Cache
Durango has a two stage caching system, depicted below.
L2 Cache
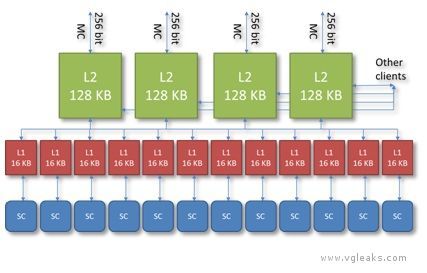
The GPU contains four separate 8-way L2 caches of 128 KB, each composed of 2048 64-byte cache lines. Each L2 cache owns a certain subset of address space. Texture tiling patterns are chosen to ensure all four caches are equally utilized. The L2 generally acts as a write-back cache—when the GPU modifies data in a cache line, the modifications are not written back to main memory until the cache line is evicted. The L2 cache mediates virtually all memory access across the entire chip, and supplies a variety of types of data, including shader code, constants, textures, vertices, etc., coming either from main RAM or from ESRAM. Shader atomic operations are implemented in the L2 cache.
L1 Cache
Each shader core has a local 64-way L1 cache of 16 KB, composed of 256 64-byte cache lines. The L1 generally acts as a write-through cache—when the SC modifies data in the cache, the modifications are pushed back to L2 without waiting until the cache line is evicted. The L1 cache is used exclusively for data read and written by shaders and is dedicated to coalescing memory requests over the lifetime of a single vector. Even this limited sort of caching is important, since memory accesses tend to be very spatially coherent, both within one thread and across neighboring threads.
The L1 cache guarantees consistent ordering per thread: A write followed by a read from the same address, for example, will give the updated value. The L1 cache does not, however, ensure consistency across threads or across vectors. Such requirements must be enforced explicitly—using barriers in the shader for example. Data is not shared between L1 caches or between SCs except via write-back to the L2 cache.
Unlike some earlier GPUs (including the Xbox 360 GPU), Durango leaves texture and buffer data in native compressed form in the L2 and L1 caches. Compressed data implies a longer fetch pipeline—every L1 cache must now have decoder hardware in it that repeats the same calculation each time the same data is fetched. On the other hand, by keeping data compressed longer, the GPU limits cache footprint and intermediate bandwidth. Following the same principle, sRGB textures are left in gamma space in the cache, and, therefore, have the same footprint as linear textures.
To see how this policy affects cache efficiency, consider an sRGB BC1 texture—perhaps the most commonly encountered texture type in games. BC1 is a 4-bit per texel format; on Durango, this texture occupies 4 bits per texel in the L1 cache. On Xbox 360, the same texture is decompressed and gamma corrected before it reaches the cache, and therefore occupies 8 bytes per texel, or 16 times the Durango footprint. For this reason, the Durango L1 cache behaves like a much larger cache when compared against previous architectures.
Just as SCs can hide fetch latency by switching to other vectors, L1 texture caches on Durango are capable of hiding L2 cache latency by continuing to process fetch instructions after a miss. In other words, when a cache miss is followed by one or more cache hits, the hits can be satisfied during the stall for the miss.
Fetch
Durango supports two types of fetch operation—image fetches and buffer fetches. Image fetches correspond to the Sample method in high-level shader language (HLSL) and require both a texture register and a sampler register. Features such as filtering, wrapping, mipmapping, gamma correction, and block compression require image fetches. Buffer fetches correspond to the Load method in HLSL and require only a texture register, without a sampler register. Examples of buffer fetches are:
- Vertex fetches
- Direct3D 10-style gather4 operations (which fetch a single unfiltered channel from 4 texels, rather than multiple filtered channels from a single texel)
- Fetches from formats that are natively unfilterable, such as integer formats
Image fetches and buffer fetches have different performance characteristics. Image fetches are generally bound by the speed of the texture pipeline and operate at a peak rate of four texels per clock. Buffer fetches are generally bound by the write bandwidth into the destination registers and operate at a peak rate of 16 GPRs per clock. In the typical case of an 8-bit four-channel texture, these two rates are identical. In other cases, such as a 32-bit one-channel texture, buffer fetch can be up to four times faster.
Many factors can reduce effective fetch rate. For instance, trilinear filtering, anisotropic filtering, and fetches from volume maps all translate internally to iterations over multiple bilinear fetches. Bilinear filtering of data formats wider than 32-bits per texel also operates at a reduced rate. Floating point formats that have more than three channels operate at half rate. Use of per-pixel gradients causes fetches to operate at quarter rate.
By contrast, fetches from sRGB textures are full rate. Gamma conversion internally uses a modified 7e4 floating-point representation. This format is large enough to be bitwise exact according to the DirectX 10 spec, yet still small enough to fit through a single filtering pipe.
The Durango GPU supports all standard Direct3D 11 DXGI formats, as well as some custom formats.
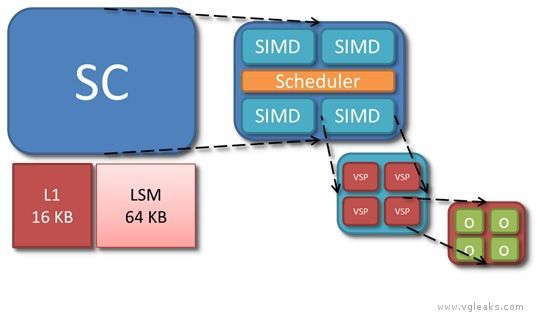
Compute
Each of the 12 Durango SCs has its own L1 cache, LSM (Local Shared Memory), and scheduler, and four SIMD units. O represents a single thread of the currently executing shader.
SIMD
Each of the four SIMDs in the shader core is a vector processor in the sense of operating on vectors of threads. A SIMD executes a vector instruction on 64 threads at once in lockstep. Per thread, however, the SIMDs are scalar processors, in the sense of using float operands rather than float4 operands. Because the instruction set is scalar in this sense, shaders no longer waste processing power when they operate on fewer than four components at a time. Analysis of Xbox 360 shaders suggests that of the five available lanes (a float4 operation, co-issued with a float operation), only three are used on average.
The SIMD instruction set is extensive, and supports 32-bit and 64-bit integer and float data types. Operations on wider data types occupy multiple processor pipes, and therefore run at slower rates—for example, 64-bit adds are one-eighth rate, and 64-bit multiplies are 1/16-rate. Transcendental operations, such as square root, reciprocal, exponential, logarithm, sine, and cosine, are non-pipelined and run at quarter rate. These operations should be used sparingly on Durango because they are more expensive relative to arithmetic operations than they are on Xbox 360.
Scheduler
The scheduler of the SC is responsible for loading shader code from memory and controlling execution of the four SIMDs. In addition to managing the SIMDs, the scheduler also executes certain types of instructions on its own. These instructions come from a separate scalar instruction set; they perform an operation per vector rather an operation than per thread. A scalar instruction might be employed, for example, to add two shader constants. In microcode, scalar instructions have names beginning with s_, while vector instructions have names beginning with v_.
The scheduler tracks dependencies within a vector, keeping track of when the next instruction is safe to run. In addition, the scheduler handles dynamic branch logic and loops.
On each clock cycle, the scheduler considers one of the four SIMDs, iterating over them in a round-robin fashion. Most instructions have a four cycle throughput, so each SIMD only needs attention once every four clocks. A SIMD can have up to 10 vectors in flight at any time. The scheduler selects one or more of these 10 candidate vectors to execute an instruction. The scheduler can simultaneously issue multiple instructions of different types—for instance, a vector operation, a scalar operation, a global memory operation, a local memory operation, and a branch operation—but each operation must act on a different vector.
General Purpose Registers
Each SIMD contains 256 vector general purpose registers (VGPRs), and 512 scalar general purpose registers (SGPRs). Both types of GPR store 32-bit data: An SGPR contains a single 32-bit value shared across threads, while a VGPR represents an array of 32-bit values, one per thread within a vector. Each thread can only see its own entry within a VGPR.
GPRs record intermediate results between instructions of the shader. To each newly created vector, the GPU assigns a range of VGPRs and a range of SGPRs—as many as needed by the shader up to a limit of 256 VGPRs and 104 SGPRs. Some GPRs are consumed implicitly by the system—for instance, to hold literal constants, index inputs, barycentric coordinates, or metadata for debugging.
The number of available GPRs can be a limiting factor in the ability of the SIMD to hide latency by switching to other vectors. If all the GPRs for a SIMD are already assigned, then no new vector can begin executing. And then, if all active vectors stall, the SIMD goes idle until one of the stalls ends.
Like most modern GPUs, the Durango GPU uses a unified shader architecture (USA), which means that the same SCs are used interchangeably for all stages of the shader pipeline: vertex, hull, domain, geometry, pixel, and compute. On Durango, GPR usage is also unified; there is no longer any fixed allocation of GPRs to vertex or pixel shading as on Xbox 360.
Constants
The Durango GPU has no dedicated registers to hold shader constants. When a shader references a constant buffer, the compiler decides how these accesses will be implemented. The compiler can specify that constants be preloaded into GPRs. The compiler may fetch constants from memory by using scalar instructions. The compiler may cache constants in the LSM.
A shader constant may be either global (constant over the whole draw call) or indexed (immutable, but varying by thread). Indexed constants must be fetched using vector instructions, and are correspondingly more expensive than global constants. This cost is somewhat analogous to the constant waterfalling penalty from Xbox 360, although the mechanism is different.
Branches
Branch instructions are executed by the scheduler and have the same ideal cost as computation instructions. Just as they do on CPUs, however, branches may incur pipeline stalls while awaiting the result of the instruction which determines the branch direction. Not-taken branches introduce subsequent pipeline bubbles. Taken branches require a read from the instruction cache, which incurs an additional delay. All these potential costs are moot as long as there are enough active vectors to hide the stalls.
Branching is inherently problematic on a SIMD architecture where many threads execute in lockstep, and agreement about the branch direction is not guaranteed. The HLSL compiler can implement branch logic in one of several ways:
- Predication – Both paths are executed; calculations that should not happen for a particular thread are masked out.
- Predicated jump – If all threads decide the branch in the same way, only the correct path is executed; otherwise, both paths are executed.
- Skip – Both paths are followed, but instructions that are executed by no threads are skipped over at a faster rate.
Interpolation
The Durango GPU has no fixed function interpolation units. Instead, a dedicated GPU component routes vertex shader output data to the LSM of whichever SC (or SCs) ends up running the pixel shader. This routing mechanism allows pixels to be shaded by a different SC than the one that shaded the associated vertices.
Before pixel shader startup, the GPU automatically populates two registers with interpolation metadata:
- One SGPR is a bitfield that contains:
- a pointer to the area of the LSM where vertex shader output was stored
- a description of which pixels in the current vector came from which vertices
- Two VGPRs contain barycentric coordinates for each pixel (the third barycentric coordinate is implicit)
It is the responsibility of the shader compiler to generate microcode prologues that perform the actual interpolation calculations. The SCs have special purpose multiply-add instructions that read some of their inputs directly from the LSM. A single float interpolation across a triangle can be accomplished by using two of these instructions.
This approach to interpolation has the advantage that there is no cost for unused interpolants—the instructions can be omitted or branched over. Conversely, there is no benefit from packing interpolants into float4’s. Nevertheless, for short shaders, interpolation can still significantly impact overall computation load.
Output
Pixel shading output goes through the DB and CB before being written to the depth/stencil and color render targets. Logically, these buffers represent screenspace arrays, with one value per sample. Physically, implementation of these buffers is much more complex, and involves a number of optimizations in hardware.
Both depth and color are stored in compressed formats. The purpose of compression is to save bandwidth, not memory, and, in fact, compressed render targets actually require slightly more memory than their uncompressed analogues. Compressed render targets provide for certain types of fast-path rendering. A clear operation, for example, is much faster in the presence of compression, because the GPU does not need to explicitly write the clear value to every sample. Similarly, for relatively large triangles, MSAA rendering to a compressed color buffer can run at nearly the same rate as non-MSAA rendering.
For performance reasons, it is important to keep depth and color data compressed as much as possible. Some examples of operations which can destroy compression are:
- Rendering highly tessellated geometry
- Heavy use of alpha-to-mask (sometimes called alpha-to-coverage)
- Writing to depth or stencil from a pixel shader
- Running the pixel shader per-sample (using the SV_SampleIndex semantic)
- Sourcing the depth or color buffer as a texture in-place and then resuming use as a render target
Both the DB and the CB have substantial caches on die, and all depth and color operations are performed locally in the caches. Access to these caches is faster than access to ESRAM. For this reason, the peak GPU pixel rate can be larger than what raw memory throughput would indicate. The caches are not large enough, however, to fit entire render targets. Therefore, rendering that is localized to a particular area of the screen is more efficient than scattered rendering.
Fill
The GPU contains four physical instances of both the CB and the DB. Each is capable of handling one quad per clock cycle for a total throughput of 16 pixels per clock cycle, or 12.8 Gpixel/sec. The CB is optimized for 64-bit-per-pixel types, so there is no local performance advantage in using smaller color formats, although there may still be a substantial bandwidth savings.
Because alpha-blending requires both a read and a write, it potentially consumes twice the bandwidth of opaque rendering, and for some color formats, it also runs at half rate computationally. Likewise, because depth testing involves a read from the depth buffer, and depth update involves a write to the depth buffer, enabling either state can reduce overall performance.
Depth and Stencil
The depth block occurs near the end of the logical rendering pipeline, after the pixel shader. In the GPU implementation, however, the DB and the CB can interact with rendering both before and after pixel shading, and the pipeline supports several types of optimized early decision pathways. Durango implements both hierarchical Z (Hi-Z) and early Z (and the same for stencil). Using careful driver and hardware logic, certain depth and color operations can be moved before the pixel shader, and in some cases, part or all of the cost of shading and rasterization can be avoided.
Depth and stencil are stored and handled separately by the hardware, even though syntactically they are treated as a unit. A read of depth/stencil is really two distinct operations, as is a write to depth/stencil. The driver implements the mixed format DXGI_FORMAT_D24_UNORM_S8_UINT by using two separate allocations: a 32-bit depth surface (with 8 bits of padding per sample) and an 8-bit stencil surface.
Antialiasing
The Durango GPU supports 2x, 4x, and 8x MSAA levels. It also implements a modified type of MSAA known as compressed AA. Compressed AA decouples two notions of sample:
- Coverage sample–One of several screenspace positions generated by rasterization of one pixel
- Surface sample– One of several entries representing a single pixel in a color or depth/stencil surface
Traditionally, coverage samples and surface samples match up one to one. In standard 4xMSAA, for example, a triangle may cover from zero to four samples of any given pixel, and a depth and a color are recorded for each covered sample.
Under compressed AA, there can be more coverage samples than surface samples. In other words, a triangle may still cover several screenspace locations per pixel, but the GPU does not allocate enough render target space to store a unique depth and color for each location. Hardware logic determines how to combine data from multiple coverage samples. In areas of the screen with extensive subpixel detail, this data reduction process is lossy, but the errors are generally unobjectionable. Compressed AA combines most of the quality benefits of high MSAA levels with the relaxed space requirements of lower MSAA levels.
// google_ad_client = "ca-pub-3409811703707400"; - Vgleaks final artículo 2 - google_ad_slot = "7576692731"; google_ad_width = 728; google_ad_height = 90;// ]]>
Moore’s Law imposes a design challenge: How to make effective use of ever-increasing numbers of transistors without breaking the bank on power consumption? Simply packing in more instances of the same components is not always the answer. Often, a more productive approach is to move easily encapsulated, math-intensive operations into hardware.
The Durango GPU includes a number of fixed-function accelerators. Move engines are one of them.
Durango hardware has four move engines for fast direct memory access (DMA)
This accelerators are truly fixed-function, in the sense that their algorithms are embedded in hardware. They can usually be considered black boxes with no intermediate results that are visible to software. When used for their designed purpose, however, they can offload work from the rest of the system and obtain useful results at minimal cost.
The following figure shows the Durango move engines and their sub-components.
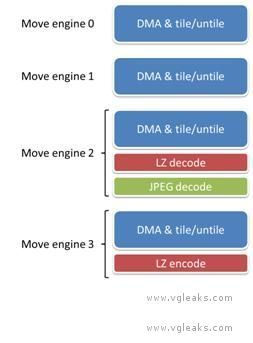
The four move engines all have a common baseline ability to move memory in any combination of the following ways:
- From main RAM or from ESRAM
- To main RAM or to ESRAM
- From linear or tiled memory format
- To linear or tiled memory format
- From a sub-rectangle of a texture
- To a sub-rectangle of a texture
- From a sub-box of a 3D texture
- To a sub-box of a 3D texture
The move engines can also be used to set an area of memory to a constant value.
DMA Performance
Each move engine can read and write 256 bits of data per GPU clock cycle, which equates to a peak throughput of 25.6 GB/s both ways. Raw copy operations, as well as most forms of tiling and untiling, can occur at the peak rate. The four move engines share a single memory path, yielding a total maximum throughput for all the move engines that is the same as for a single move engine. The move engines share their bandwidth with other components of the GPU, for instance, video encode and decode, the command processor, and the display output. These other clients are generally only capable of consuming a small fraction of the shared bandwidth.
The careful reader may deduce that raw performance of the move engines is less than could be achieved by a shader reading and writing the same data. Theoretical peak rates are displayed in the following table.
| Copy Operation | Peak throughput using move engine(s) | Peak throughput using shader |
| RAM ->RAM | 25.6 GB/s | 34 GB/s |
| RAM ->ESRAM | 25.6 GB/s | 68 GB/s |
| ESRAM -> RAM | 25.6 GB/s | 68 GB/s |
| ESRAM -> ESRAM | 25.6 GB/s | 51.2 GB/s |
The advantage of the move engines lies in the fact that they can operate in parallel with computation. During times when the GPU is compute bound, move engine operations are effectively free. Even while the GPU is bandwidth bound, move engine operations may still be free if they use different pathways. For example, a move engine copy from RAM to RAM would not be impacted by a shader that only accesses ESRAM.
Generic lossless compression and decompression
One move engine out of the four supports generic lossless encoding and one move engine supports generic lossless decoding. These operations act as extensions on top of the standard DMA modes. For instance, a title may decode from main RAM directly into a sub-rectangle of a tiled texture in ESRAM.
The canonical use for the LZ decoder is decompression (or transcoding) of data loaded from off-chip from, for instance, the hard drive or the network. The canonical use for the LZ encoder is compression of data destined for off-chip. Conceivably, LZ compression might also be appropriate for data that will remain in RAM but may not be used again for many frames—for instance, low latency audio clips.
The codec employed by the move engines is LZ77, the 1977 version of the Lempel-Ziv (LZ) algorithm for lossless compression. This codec is the same one used in zlib, glib and other standard libraries. The specific standard that the encoder and decoder adhere to is known as RFC1951. In other words, the encoder generates a compliant bit stream according to this standard, and the decoder can decompress certain compliant bit streams, and in particular, any bit stream generated by the encoder.
LZ compression involves a sliding window and operates in blocks. The window represents the history available to pattern-match against. A block denotes a self-contained unit, which can be decoded independently of the rest of the stream. The window size and block size are parameters of the encoder. Larger window and block sizes imply better compression ratios, while smaller sizes require less calculation and working memory. The Durango hardware encoder and decoder can support block sizes up to 4 MB. The encoder uses a window size of 1 KB, and the decoder uses a window size of 4 KB. These facts impose a constraint on offline compressors. In order for the hardware decoder to interpret a compressed bit stream, that bit stream must have been created with a window size no larger than 4 KB and a block size no larger than 4 MB. When compression ratio is more important than performance, developers may instead choose to use a larger window size and decode in software.
The LZ decoder supports a raw throughput of 200 MB/s compressed data. The LZ encoder is designed to support a throughput of 150-200 MB/s for typical texture content. The actual throughput will vary depending on the nature of the data.

JPEG decoding
The same move engine that supports LZ decoding also supports JPEG decoding. Just as with LZ, JPEG decoding operates as an extension on top of the standard DMA modes. For instance, a title may decode from main RAM directly into a sub-rectangle of a tiled texture in ESRAM. The move engines contain no hardware JPEG encoder, only a decoder.
The JPEG codec used by the move engine is known as ISO/IEC 10918-1, which was the 1994 JPEG committee standard. The hardware decoder does not support later standards, such as JPEG 2000 (wavelet encoding) or the format known variously as JPEG XR, HD Photo, or Windows Media Photo, which added a number of extensions to the base algorithm. There is no native support for grayscale-only textures or for textures with alpha.
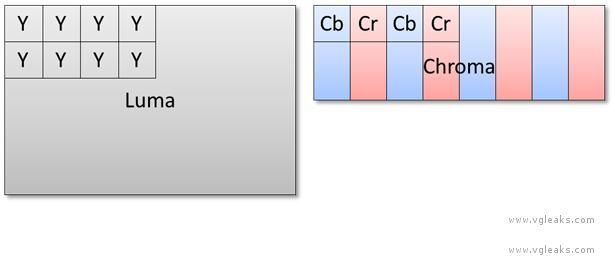
The move engine takes as input an entire JPEG stream, including the JFIF file header. It returns as output an 8-bit luma (Y or brightness) channel and two 8-bit subsampled chroma (CbCr or color) channels. The title must convert (if desired) from YCbCr to RGB using shader instructions.
The JPEG decoder supports both 4:2:2 and 4:2:0 subsampling of chroma. For illustration, see Figures 2 and 3. 4:2:2 subsampling means that each chroma channel is ½ the resolution of luma in the x direction, which implies a footprint of 2 bytes per texel. 4:2:0 subsampling means that each chroma channel is ½ the resolution of luma in both the x and y directions, which implies a footprint of 1.5 bytes per texel. The subsampling mode is a property of the compressed image, specified at encoding time.
In the case of 4:2:2 subsampling, the luma and chroma channels are interleaved. The GPU supports special texture formats (DXGI_FORMAT_G8R8_G8B8_UNORM) and tiling modes to allow all three channels to be fetched using a single instruction, even though they are of different resolutions.
JPEG decoder output, 4:2:2 subsampled, with chroma interleaved.

In the case of 4:2:0 subsampling, the luma and chroma channels are stored separately. Two fetches are required to read a decoded pixel—one for the luma channel and another (with different texture coordinates) for the chroma channels.
JPEG decoder output, 4:2:0 subsampled, with chroma stored separately.
Throughput of JPEG decoding is naturally much less than throughput of raw data. The following table shows examples of processing loads that approach peak theoretical throughput for each subsampling mode.
Peak theoretical rates for JPEG decoding.
|
Subsampling mode |
Peak performance |
Raw data rate |
|
4:2:2 |
two 720p images/frame at 60 Hz | 2 × 1280 × 720 × 2 bytes × 60 Hz = 221 MB/s |
|
4:2:0 |
two 1080p images/frame at 60 Hz | 2 × 1920 × 1080 × 1.5 bytes × 60 Hz = 373 MB/s |
System and title usage
Move engines 1, 2 and 3 are for the exclusive use of the running title.
Move engine 0 is shared between the title and the system. During the system’s GPU time slice, the system uses move engine 0. During the title’s GPU time slice, move engine 0 can be used by title code. It may also be used by Direct3D to assist in carrying out title commands. For instance, to complete a Map operation on a surface in ESRAM, Direct3D will use move engine 0 to move that surface to main memory.
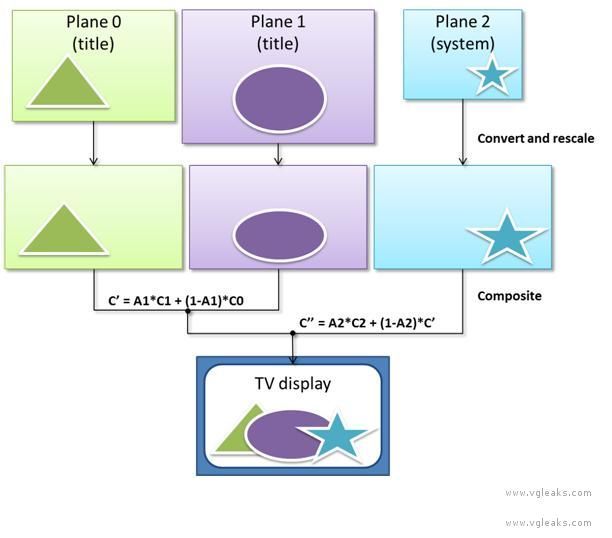
The Durango GPU supports three independent display planes, which are conceptually similar to three separate front buffers. The display planes have an implied order. The bottom plane is combined with the middle plane using the middle plane’s alpha channel as an interpolation factor. The result of this operation is combined with the top plane using the top plane’s alpha channel as an interpolation factor. Blending occurs at 10-bit fixed-point precision. The following diagram illustrates the sequence of operations.
{kind=link}
The three display planes are independent in the following ways, among others:
- They can have different resolutions.
- They can have different precisions (bits per channel) and formats (float or fixed).
- They can have different color spaces (RGB or YCbCr, linear or sRGB).
Each display plane can consist of up to four image rectangles, covering different parts of the screen. The use of multiple screen rectangles can reduce memory and bandwidth consumption when a layer contains blank or occluded areas.
The display hardware contains three different instances of various image processing components, one per display plane, including:
- A hardware scaler.
- A color space converter.
- A border cropper.
- A data type converter.
Using these components, the GPU converts all three display planes to a common output profile before combining them.
The bottom and middle display planes are reserved for the running title. A typical use of these two planes is to render the game world at a fixed title-specified resolution, while rendering the UI at the native resolution of the connected display, as communicated over HDMI. In this way, the title keeps the benefits of high-quality hardware rescaling, without losing the pixel-accuracy and sharpness of the interface. The GPU does not require that all three display planes be updated at the same frequency. For instance, the title might decide to render the world at 60 Hz and the UI at 30 Hz, or vice-versa. The hardware also does not require the display planes to be the same size from one frame to the next.
The system reserves the top display plane for itself, which effectively decouples system rendering from title rendering. This decoupling removes certain output constraints that exist on the Xbox 360. For example, on Durango the system can update at a steady frame rate even when the title does not. The system can also render at a lower or higher resolution than the title, or with different color settings.
진인환도 아니고 스마일도 아닌데 루리웹이 직업인 인간이 드물게 하나씩 있습니다. 이글싼 splay도 개중 하나 2005년에도 플삼가지고 이지랄 떨었었음ㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷ
지겨워. 이제 그만좀 올려요
그래도 고마해라..마이 봤다 아이가...
좋은 정보네요. 물론 읽지는 못했습니다.
똑같은것만 몇번째인지
흠... 그렇군요...
물론 이해는 하지 못했습니다
뭔 소리야 한글로 요약 좀 해봐
상세설명은 맞는데 안한글이네요
지겨워. 이제 그만좀 올려요
똑같은것만 몇번째인지
좋은 정보네요. 물론 읽지는 못했습니다.
왓떠헬.... 그러니까 지금 XBOX360보다 얼마나 좋은거임??
블옵2 풀옵 60프레임 1080p는 가능?
가능할덧
그정도는 가능할듯..
한단어 요약좀..
가장 위에 있는 그림있는 부분은 올라온적 있지만 아래는 올라온적이 없죠..
그래도 고마해라..마이 봤다 아이가...
위 자료는 처음 올리는 자료인것인데.....
그래서 얼마 준비하면 되나요?
진인환도 아니고 스마일도 아닌데 루리웹이 직업인 인간이 드물게 하나씩 있습니다. 이글싼 splay도 개중 하나 2005년에도 플삼가지고 이지랄 떨었었음ㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷㄷ
2007년부터 페르소나3FES 디스크 오류 리콜사태 때문에 그때부터 루리웹 본격적으로 들어왔지만 이정도면 참 정말 대단함 어째 2007년부터 계속해서 계속 계속 계속
대한민국이 스플레이임?
ㅇㅇ 05년도때 배슬기 안경쓴 사진을 프사로 썼던 그 스플레이 맞음ㅇㅇ
스플레이 이양반이 원래 벽하고 이야기 하는느낌이라 유저들이 까니깐 몇번 스플레이도 응수함 근데 빡쳤는지 어느순간부터 태클거는 덧글은 상대를 안함.... 그러다보니 점점 더 벽이 되어가고 있음 ㅇㅇ
저를 보고 그분 얘기 많이들 하는데... 저랑 다른 분입니다.. 예전에 그분 말고도 다른분 얘기도 나왔었는데...까먹었지만..암튼..모두 아니에요..ㅎㅎ
07년까지 활동한 splay 때와 08년부터 7654321 때와 10년부터 활동한 한국 때나 글쓰는게 완전히 같은데요?
splay 시절에 모니터좀 그만쳐다보고 사람답게살라고 듣기싫은 충고 길게좀했더니 글삭하더군요. 아 얘도 뭔가 와닿긴했나보다 싶었는데 닉변해서 다시 등장ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 그게 한국이었음
저는 7654321이랑 한국을 거쳐 대한민국이라는 닉을 사용하고 있습니다. splay라는 닉은 누군지도 모르는데..저랑 역으는지 이해가 안되네요..ㅎㅎ
닉세탁보소.. splay 인거 뻔히 아는데 아닌척은... 인간아
어떻게 스플레이가 아닌 척을 하지 진짜 ㅋㅋㅋㅋㅋㅋㅋ 동트기 전에 세번 예수를 부정한 베드로여 ㅋㅋㅋㅋ
그래서 플삼판 메기솔이 존나 좋다고 했다가 된통 당했지요 물론 이분 잘못은 아니지만요
결론은 이분글은 그냥 넘어가는게 낫습니다
제가 말하는게 아니라 유로게이머의 자료입니다. 티어링이 제품판에서는 해결된것이지요. 참고로 상세 차이점 http://gaia.ruliweb.com/gaia/do/ruliweb/default/ps/101/read?articleId=16538383&bbsId=G005&itemId=421&pageIndex=2
흰건 배경이오~ 까만건 글자라~ 거기까지만 알겠네요.
그냥 나오면 사면 됩니다~
아 뭐래는거야~
성능은 관심 없다.....삼돌이 처럼 pc로 만든거 포팅하기 얼마나 쉬운지 그리고 그래픽 기술 적용이 쉬운지만 관심있는데...그정보는 개발툴이 나와야 할꺼니..한참 먼듯
기기자체가 삼돌처럼 ppc가 아니라 x86기반프로세서라서 거의 구엑박같은 구조라고봐도됩니다 (플4도 마찬가지)
삼돌보다 더쉬울듯..
그 래 서 스펙 으로 봤을때 . PS4가 좋아 XBOX720 좋은건가요?
플사가 좋아요.
지금까지 유출된것만 볼때 PS4가 더 좋을것으로 예상되는 상황..
글자도 못알아먹겠지만 그림도 못알아먹겠네
뭔소리야 그냥 둘다사야지
x86기반인 구엑박은 거치형 콘솔중에서 최고의 에뮬머신이었지 x86기반인 엑박720도 그렇게 될런가???
영어 ㅜ ㅜ 누가번역좀
자료를 들고 왔으면 그래도 번역을 하던가 요약을 하던가 해라. ㅡㅡ
죄다 영어긴 하지만.. 솔직히 한글로 번역을 해줘도 뭔소린지 못알아 먹을거 같네요.
번역 하나 마다 알아 먹을 사람은 소수이고 알아먹는 사람만 보면 되는것임.. 저도 저거 다 모르고 일부분은 이해되고 모르겠는 부분도 있고..그렇네요..
뭐라는겨..
해석이라도 해줘야지 근데 추억의 스플레이가 아직도 있구나...
읽어보니 저 jpeg은 그냥 표준 썼다는 소리이니 듀랑고 스펙글에 들어갈 필요가 없어 보이는데 하기사 스플레이에게 뭘 바라냐. 이거 제대로 다 읽고 글 올리긴 하냐?
아.. 네... 좋은 정보군요...네 그렇다고요...
지금이라도 360 팔까
나 유출당한고야??
물논
일본 대지진 났을 때도 주구장창 일본 정부 공식 발표만 시간대별로 정리해 올리면서 원전 터질까 걱정하는 사람들 비웃는 투로 공식 자료만 믿는다느니 빈정거리다가 원자력 발전소 한기씩 터져나가니까 싹 지우고 대지진 소식계에서 잠적했음.
ㅋㅋㅋㅋㅋㅋㅋ
제가 말하는것은 일본이 뭔짓해던간에 우리나라에는 티끌도 영향 없다는 말을 했죠. 그리고 최악이어도 일본 도쿄 사는사람들 피해 별로 없을것이라고도 말했죠.. 후쿠시마 그쪽만 지역만 죽음의 도시가 될것이라고 말했죠... 실제로도 그렇게 되었구요.. 지금도 너무 확대 해석 과장 하는 사람들이 너무 많음..
그 해석이 과장인지 아닌지 평가하기에는 아직 시간이 턱도 없이 부족함. 글고 그때 그런 소리만 한 것이 아닐텐데. 안터질거라고도 했고, 1호기 터진 후에는 2, 3호기는 안정되어간다고도 했을텐데.
방사능 카카오매스 가공공장의 원재료가 롯데제과로 롯데제과로..
요즘세상이 소같은 가축만 트랙킹되는게 아닌데.. 식가공재료 원산지/가공지 정보 조회 다 되요.
Maine Coon Maine Coon 저는 미국 일본 등이 제시하는 객관적 데이터를 근거로서 말하는데 말도 안되는 이상한 소리하니 말이 안통하는것.. 그리고 일본측에서 말하는것 밖에 객관적 데이터가 없는데 그럼 누구말을 믿나? 또 미국측에서 나온 최악의 상황자료에서도 그닥 큰 범위까지 피해가 확산되는것은 아니었죠. 그리고 유럽쪽 동해 방사능 영향 준다는그림도 인체에 영향없는 것이었구요.. 결과론적을 제가 말한것처럼 되었으니...ㅎㅎ
그때도 일본 정부가 하는 발표를 객관적인 사실이라고 원전 안터진다고하다 하나씩 터져나가니까 그 글들은 싹 지웠으면서 아직도 객관적 타령하고 자빠졌네.
Maine Coon 말 지어내지 마시길..ㅎㅎ 저는 정부기관자료나 믿은 만한 자료가지고만 얘기합니다. 그 데이터 자체를 말하는것이죠...이상한 소설 안쓰고.... 결과론적으로 제 말처럼 되었진것이구요.. 말도 안되게 과장해서 다 죽느니 뭐니 이상한 말들 하는 사람이 너무 많았음..
호오.. 그렇군.. 역시... 음...
IT용어가 많이 나와서 관심있거나 관련학과 아니면 잘 모를듯.ㅋㅋ 데이터 펌핑이 예상대로 잘 되면야 뭐.... 나오는거보고 괜찮은거 사고 하나는 나중에 가격싸지면 사야지.ㅋ
무엇보다 gpu성능에서 ps4가 압도적으로 좋네요 키넥트 내장한다고 경쟁기기에 비해서 상당히 저성능으로 만드는 모양인데 내세울만한 독점작이 별로 없고 멀티는 유로인 엑박측이 무슨 자신감인지 신기함
어.. 이댓글 플3때도 본거같아!!
헤일로랑 기어스만 믿고간다이건가..
사실 그 두개 때문에 못 갈아타는 중
난 또 뭔가 새로운 거라도 있는 줄 알았더니 존나게 같은 거 우려먹네. 편집증이야 편집증.
이인간 지가 splay 였던 시절이 쪽팔리나보네.. 이제와서 아닌척 닉세탁 ㅉㅉㅉ 닉세탁 할거였으면 splay 정지되고 나서 바로했어야지... 다른 아뒤로 들어와서 몇년째 이러고 있으면서 이제와서 아니다?? 고만좀 해라. 편집증 환자야
병불허전 스프머시기
저거 자료를 잘 보면 램이 DDR3 68GB/s 라고 나오는데.... 이거 1066Mhz를 8채널램으로 돌려야 나오는 전송량인데 진짜로 이렇게 나오려는 건지 모르겠네요? 8채널이면 양산에 문제있지 않나요?
딴건 필요없고 칩생산이 12월부터 시작되었다면 2/4분기안에 출시될 확률이 매우 높다는 이야기. 크리스마스 시즌은 훼이크
플4랑 비교하면 어느정도지
흠...