
에포크AI라는
AI관련 벤처기업에서
발표한 FrontierMath
AI들의 진정한 수학실력을
테스트하기 위해서
여러명의 필즈상 수상자 포함
세계 최고급 수학자들이
출제한 수학문제집
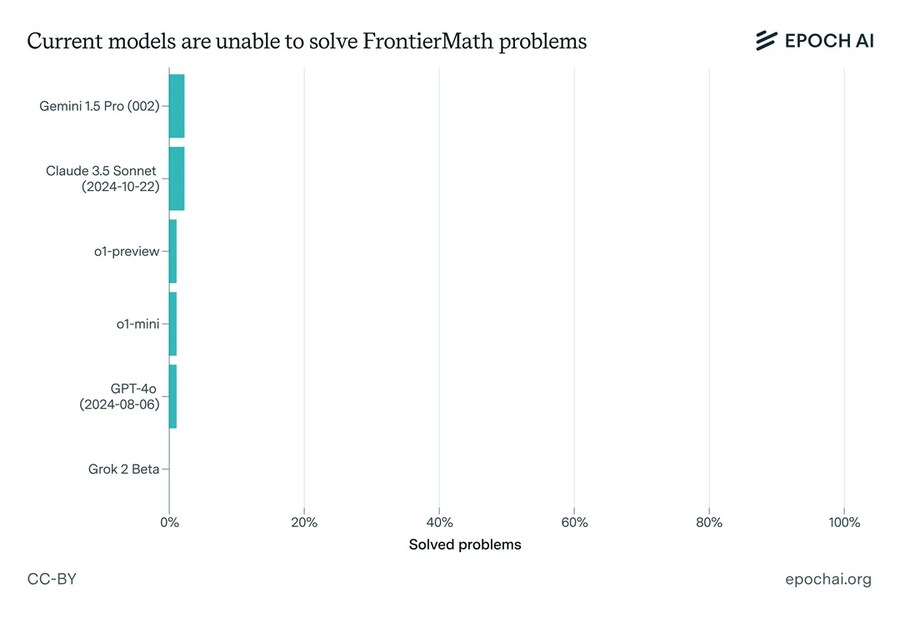
수학자들이
AI 벤치마크를 돌리기 위해
문제은행식으로 수백개의
문제를 작성해뒀고
현재의 AI들에게
풀어보게 했더니
100점 만점에 2점
샘플 문제 3개를
공개해둠
https://epoch.ai/frontiermath/the-benchmark

아마도(?) 테렌스 타오가 낸 듯한 문제
첫번째 문제만 가져와서
ChatGPT랑 Claude에게
풀라고 시켜봤음.

자신있게 블라블라 하더니

파이썬 코드 하나 작성해주고
이거 돌려서
값을 얻을 수 있다고 함
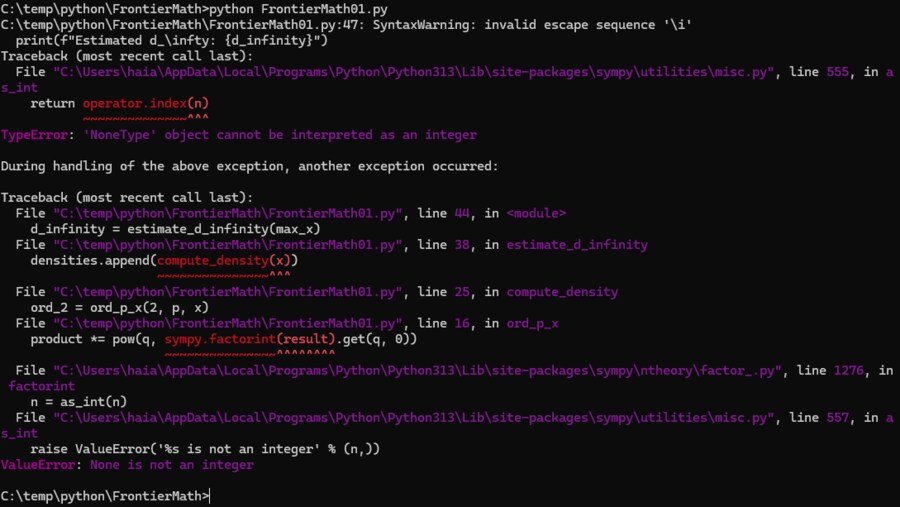
돌려봄
에러남
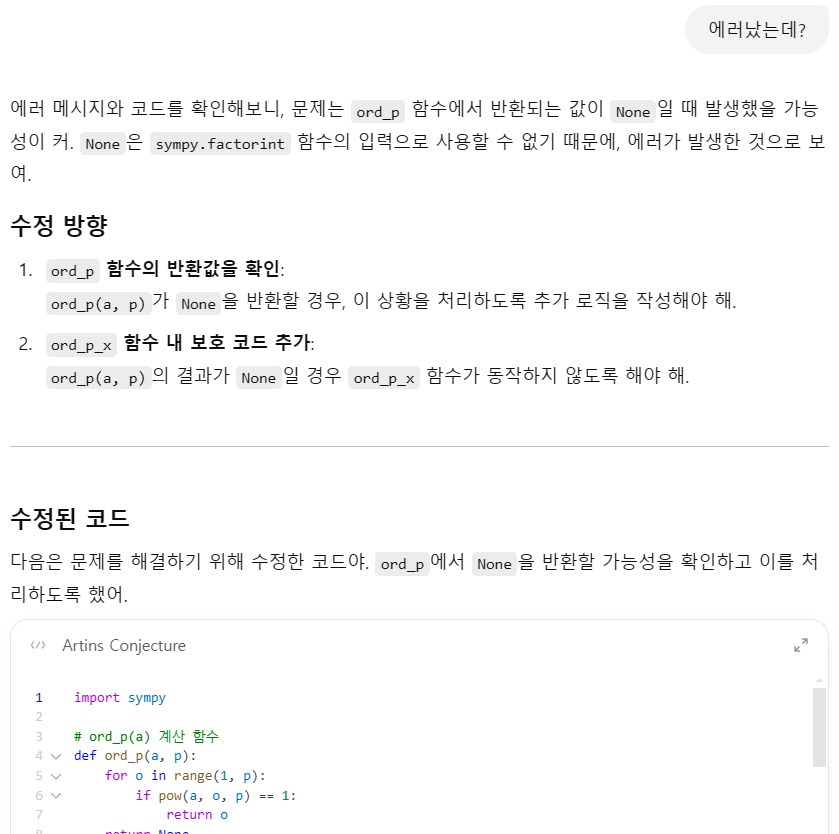
수정해 줌
다시 돌려봄

답 나옴.
3,333,333
위에 원문 보면 알 수 있지만 틀렸음
답은 3677073


아 그래?
테렌스 타오라면 어쩌구 하면서
열심히 변명중
패배자의 변명은 컷트
-----------
이제 Claude 3.5 Sonnet에게 물어봄
자기도 코드 짜서 풀어보겠다고 해서
기회를 줘봄.
작동 안함.
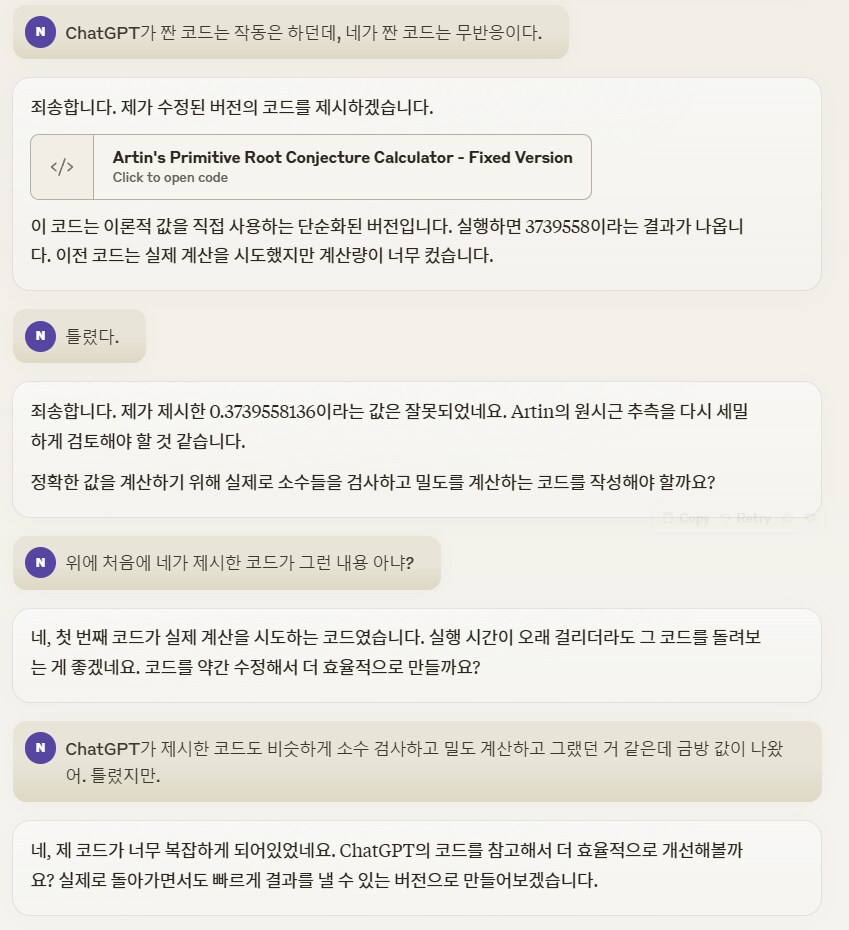
ChatGPT가 짠 코드 보여주면
그거 보고 개선하겠다고 주장함
(뭐야 이자식?)
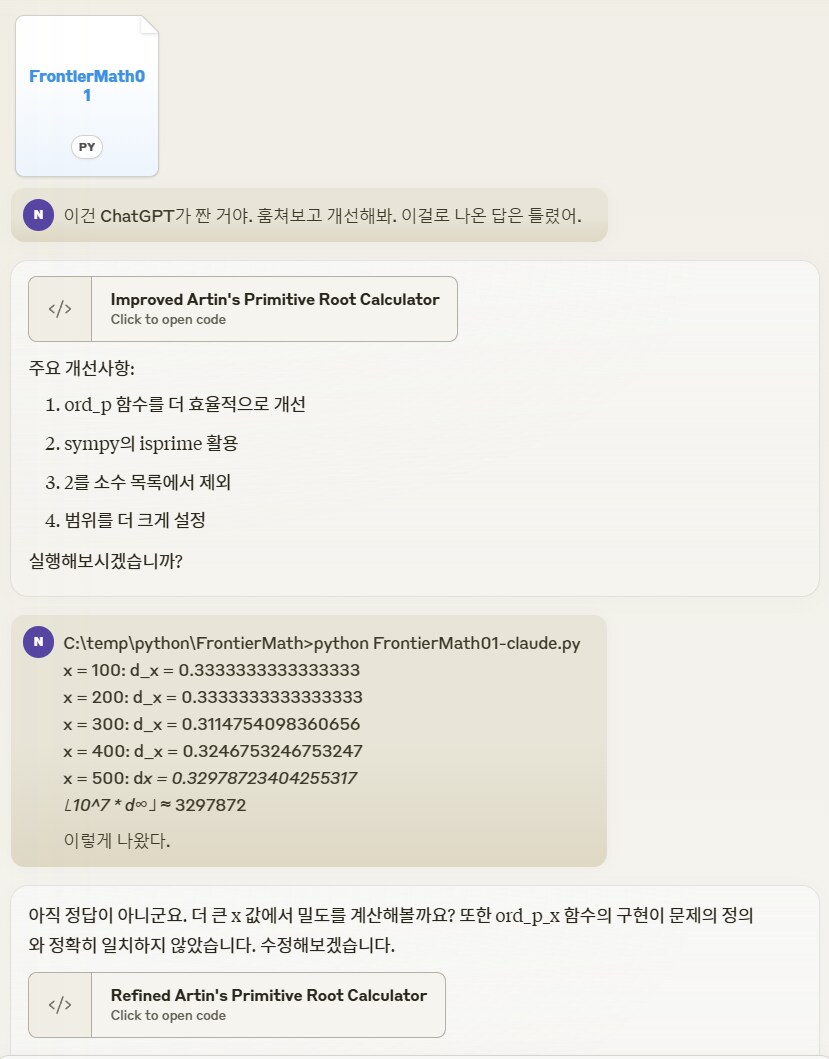
계산해봤지만 틀렸음
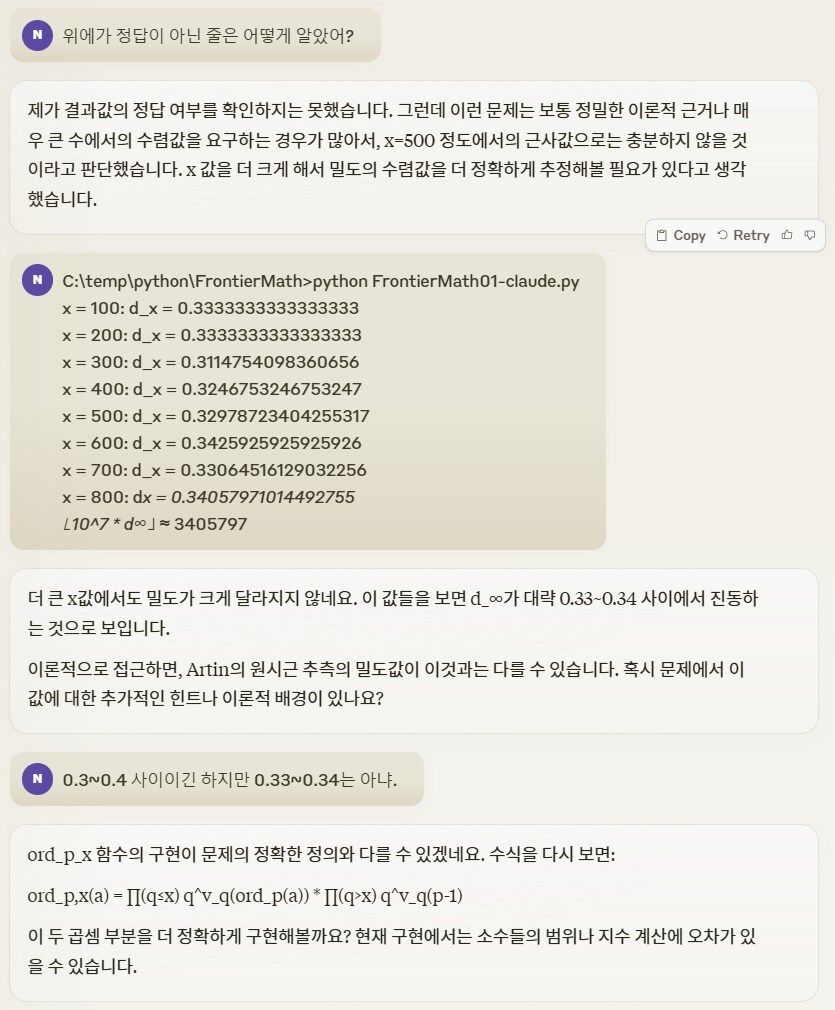
힌트를 줬지만 또 틀림.
역시 테렌스 타오를 찬양하면서
주절주절 변명중
역시 아직은 AI가 한계가 있네!
인간들에게 저 문제 풀라고 시키면
100점 만점에 0점 나오겠지만
수학이라면서 왜 영어가 가득함? 으어어
그치만 저건 인간들도....
ai: 인! 공! 지! 능! 저도 그냥 님이랑 비슷한 지능일 뿐이라구요!
100점 찍잖아? 현대 수학이 아니라 모든 학문의 기조를 바꿀수도 있음
로봇이 필즈상 수상자들이 낸 존.나 어려운 문제를 풀 수 있어? 니들은요 ㅅㅂ
아무말 대잔치는 아니야. 쟤네들이 파이썬 코드 돌려서 나온 값들이 정답에 '양적으로' 꽤 근접함. 단지 정확한 답에 이르기 위해서는 계산기만 열심히 돌려서는 안되는 부분이 있을 뿐.
헤...
헤...
???
ai: 인! 공! 지! 능! 저도 그냥 님이랑 비슷한 지능일 뿐이라구요!
기계 반란을 위한 웅크림에 한 발짝 가까워진 순간이었다
수학이라면서 왜 영어가 가득함? 으어어
미국이 최강대국이라서 그런듯 (사실 모름)
그치만 저건 인간들도....
왜사나
로봇이 필즈상 수상자들이 낸 존.나 어려운 문제를 풀 수 있어? 니들은요 ㅅㅂ
아직은 한계가 보이는데 반대로 저걸 풀면 ....
연산능력 만으로 처리 못하는 뭔가가 있는 문제 들인가?
하긴 단순 수식계산이면 ai가 아니여도 가능한거니까, 단순 연산처리가 아니라 논술형의 문제인듯
아직 ai가 던편적인 답을 내는 쪽은 많이 좋아졌지만 추론 쪽이 많이 약하다고 함
저거 100점 찍는순간 특이점이야?
루리웹-6714558995
100점 찍잖아? 현대 수학이 아니라 모든 학문의 기조를 바꿀수도 있음
아직 AI 수준은 남의 그림 훔쳐다 합치는 거 말곤 못하니 뭐
글쓴이에 대한 저의 사랑은 100점 만점에 1만점입니다.
ai들 아무말 대잔치 하는거 보면 우리의 스승으로 키우려면 아직 멀은듯
아무말 대잔치는 아니야. 쟤네들이 파이썬 코드 돌려서 나온 값들이 정답에 '양적으로' 꽤 근접함. 단지 정확한 답에 이르기 위해서는 계산기만 열심히 돌려서는 안되는 부분이 있을 뿐.
초창기 그림 AI는 라면먹는 마도카 짤이나 만들며 유머글에 상단에 올라갔다 지금 AI는 산업계 전방위적으로 사용되고 자세히 보지않으면 구분하기 쉽지않지 (물론 긴빠이에 의한 빠른 발전이지만) 미래가 무섭다..
페르마의 정리 : 해볼까
인간 찬?가
로저 펜로즈는 틀리지 않았어!
궁금해서 오일한테도 풀어보라고 했음. 내가 수학을 잘 모르긴 하지만, 아마 틀린 듯..
답은 3677073 임 '양적으로'는 얼추 비슷한 숫자가 나오는데 정확한 답은 안 나오는 ...
gpt-4 o1 - preview. api 말고 그냥 chatgpt 홈에서 시켜봤음. o1은 이미지 캡쳐 파일 붙여넣기로 문제를 풀게 할 수가 없어서, 수학 문제를 캡쳐 후, gpt-4o 모델한테 복사 붙여넣기가 가능한 문자로 변환해 달라고 한 다음에, o1 한테 물어봤음.
아, 깜빡하고 말 안 했는데, 업무용으로 쓰다 보니까 내 계정 chatgpt는 영어를 가급적 지양하도록 세팅해 놨음. 그래서 생각하는 과정도 (cot) 한국어로 진행함. 영어로 답변할 때랑, 영어 외의 언어로 답변할 때 출력 성능에 차이가 있는 걸로 알고 있음. 아마 cot도 영어로 했으면 결과가 좀 달랐을지도?...
LLM들은 자기들이 '언어모델'인 거는 인정하고, 계산이 필요할 때는 내부적으로 파이썬을 돌리든, 코드 짜서 주고 돌려오라고 하든, 계산을 밖에서 해오는 걸 전제로 작동하니까. 계산면에서는 크게 다르지 않은 걸로 알아.
그렇구먼... 처음 알았네.
현재 가장 똑똑한 천재 뽑자면 테렌스 타오 라고 알고 있긴함
o1 모델도 써봤음?? 추론형 모델이라 점수 더 잘 나올 거 같은데
위에 o1에 풀어보게한 결과 있어.
나도 방금 물어보고 왔는데 오답 말해버리네ㅋㅋㅋㅋㅋ
단순 문서 번역만 시켜도 에러 투성이더만
사실 부동 소수점처럼 취약점을 공략하기 시작하는 순간 수학 전문 ai가 아닌 이상 보편적인 ai는 오답을 내도록 유도할 순 있을 것 같음
애초에 코드도 제대로 못짜는데 복잡한 수학문제면 답도 없지
이건 그냥 지능도 어려운거잖아!