
이건 지금 핫한 Novel AI의 이미지생성 인공지능 안내페이지에 있는 내용인데
Stable Diffusion 기반 모델이라고 적혀 있음
Stable Diffusion은 요즘 굉장히 핫한 또다른 이미지 생성 인공지능인데 사이트는 여기임 #
위키백과에도 나와있고 깃헙에도 나와있지만 얘네는 2022년도에 발표된 'High-Resolution Image Synthesis with Latent Diffusion Models' 라는 논문에서 소개된 latent diffusion model이라는 것을 사용하고 있다고 함
그렇다면 이 latent diffusion model이라는 놈이 이 인공지능이 돌아가게 해주는 알고리즘이라는 건데 이 놈을 소개하는 논문의 초록은 다음과 같음
'By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs. | 이미지 형성 프로세스를 노이즈 제거 자동 인코더의 순차적 응용 프로그램으로 분해함으로써 확산 모델(DM)은 이미지 데이터 및 그 이상에서 최첨단 합성 결과를 달성한다. 또한, 그들의 공식화는 재교육 없이 이미지 생성 프로세스를 제어하는 가이드 메커니즘을 허용한다. 그러나 이러한 모델은 일반적으로 픽셀 공간에서 직접 작동하기 때문에 강력한 DM의 최적화는 종종 수백일의 GPU를 소비하며 순차적 평가로 인해 추론 비용이 많이 든다. 품질과 유연성을 유지하면서 제한된 계산 리소스에 대한 DM 교육을 가능하게 하기 위해, 우리는 그것들을 강력한 사전 훈련된 자동 인코더의 잠재 공간에 적용한다. 이전 작업과 달리, 그러한 표현에 대한 확산 모델을 훈련하면 복잡성 감소와 세부 보존 사이의 거의 최적의 지점에 처음으로 도달할 수 있어 시각적 충실도가 크게 향상된다. 교차 주의 레이어를 모델 아키텍처에 도입함으로써 확산 모델을 텍스트 또는 경계 상자와 같은 일반적인 조건부 입력을 위한 강력하고 유연한 생성기로 전환하고 고해상도 합성이 컨볼루션 방식으로 가능해진다. 우리의 잠재 확산 모델(LDM)은 무조건적인 이미지 생성, 의미론적 장면 합성 및 초해상도 등 다양한 작업에서 이미지 인페인팅을 위한 새로운 최첨단 성능을 달성하는 동시에 픽셀 기반 DM에 비해 계산 요구 사항을 크게 줄인다.(papago)'

아무튼 기존에 있던 Diffusion Model이 있는데 이녀석을 더 쩔게 개선했다 이말인...듯함
그렇다면 이 Diffusion Model의 작동방식이 조금 더 근본적인 알고리즘이 되는것인데
이놈은 2015년도에 처음 주장되었고 이를 해설하는 글도 인터넷에 꽤나 많이 나옴
....

온갖 어려운 수식과 개념이 난무하지만 최대한 이해해본다면
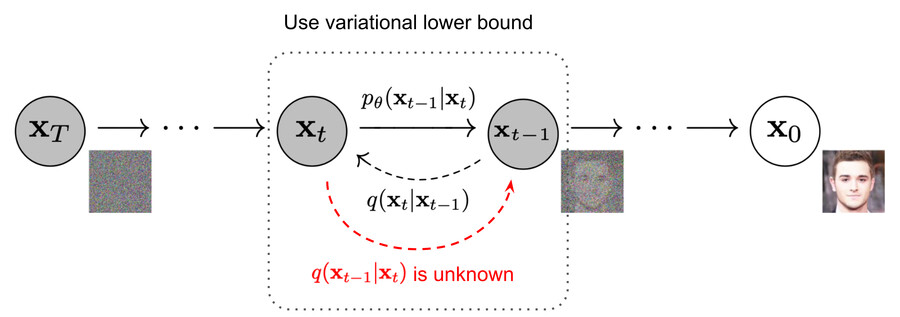
출처#https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
이미지를 서서히 노이즈화 시키는 과정 p가 있고 (그림에서 X_0 에서 X_T로)
노이즈화된 이미지를 서서히 원본 이미지로 복구하는 과정 q가 있는데
이 두 과정 모두 수학적으로 계산 증명이 됨 (수식 보고 싶은 사람은 위의 영상이나 #여기로...)
그래서 이 두 과정을 수행할때 q에서 쓰이는 수치들이 학습된다고 하는 거 같음
즉 노이즈를 이미지로 복구할때 어떤 수치들이 쓰여야 할지 학습한다는 거

그리고 학습을 할때 키워드들을 줘서 노이즈로 부터 이미지를 생성할때 활용?한다는듯
이 링크에 Diffusion Model의 원리부터 Latent Diffusion Model까지 설명되어 있던데 나는 사전지식이 아직 부족해서 100% 이해는 못하겠더라 혹시 관심있는 사람 있으면 읽어봐봐
아무튼.... 신기....
예전에 신문 흑박사진에서 사람얼굴 추출하는거 봤는데 그기술이 이젠 부담없이 쓰이는구나
겸사겸사 그 단어가 부여하는 가중치가 학습 과정에서 과도한 학습을 통해서 그 어떤 노이즈를 줘도 그거에 대응하는 가중치를 너무 학습해서 원본과 흡사한 이미지를 뽑아낸다면 이런 걸 과적합이 됐다고 하던가... 보통 특정 단어를 표현하는 학습 데이터가 적으면 과적합이 일어나지 않도록 조정하거나 해서 학습 자료가 적은 단어인 경우에는 정밀도가 굉장히 낮다고 알고 있음