
ffmpeg 이라고 위의 설명처럼 영상,음악,사진의 인코딩 디코딩을 해주는 툴이 있음.

최근 avx512를 어셈블리 코딩을 통해 적용한 결과 94배 성능 향상을 이루어 냈다.
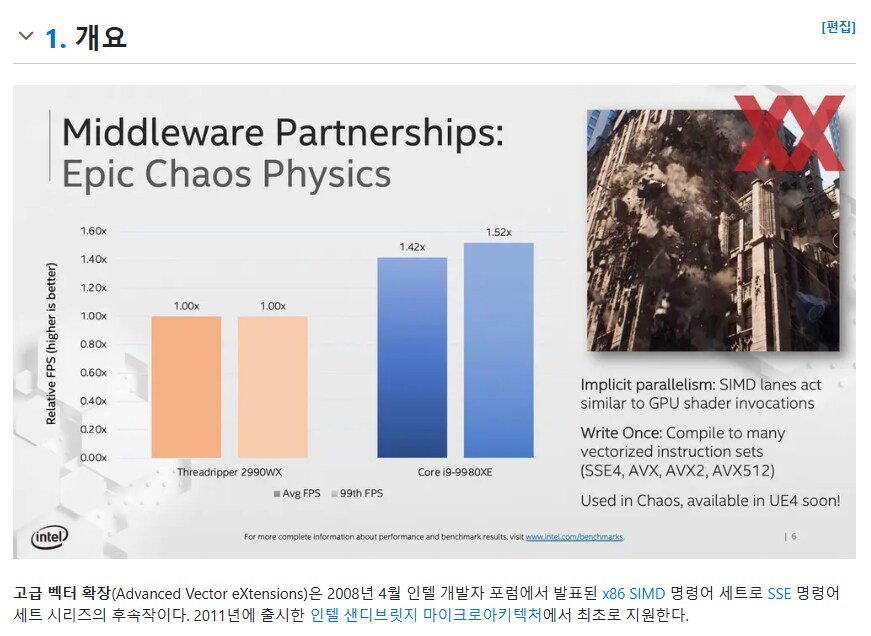
AVX-512(Advanced Vector Extensions 512)는 인텔이 개발한 최신 SIMD(Single Instruction, Multiple Data) 명령어 세트 중 하나로, 512비트의 벡터 길이를 지원합니다. 이 명령어 세트를 사용하면 여러 이유로 CPU 연산 속도가 더 빨라집니다.
1. 병렬 연산의 증가
- AVX-512는 한 번에 512비트의 데이터를 처리할 수 있습니다. 이는 AVX(256비트)나 SSE(128비트)에 비해 두 배에서 네 배가량 긴 데이터 길이를 지원하는 것입니다.
- 단일 명령어로 동시에 더 많은 데이터를 처리할 수 있으므로 데이터 병렬성이 높은 작업에서 성능이 크게 향상됩니다. 예를 들어, 부동소수점 연산을 병렬로 많이 수행하는 경우 AVX-512가 유리합니다.
2. 넓어진 레지스터 집합
- AVX-512에서는 32개의 512비트 ZMM 레지스터가 추가됩니다(기존에는 16개). 이를 통해 동시에 더 많은 데이터를 저장하고 처리할 수 있어 레지스터 재사용의 빈도를 줄일 수 있으며, 이는 전체적인 연산 효율성을 높입니다.
- 특히 복잡한 벡터 연산을 수행할 때 더 많은 레지스터를 활용해 병목 현상을 줄이는 데 도움이 됩니다.
3. 마스크 레지스터 지원
- AVX-512는 추가적으로 8개의 64비트 마스크 레지스터를 지원해, 조건부 벡터 연산을 효율적으로 처리할 수 있습니다.
- 이 마스크 레지스터들은 데이터 선택이나 특정 연산을 수행할 때 유연성을 제공하여, 조건에 맞는 데이터에만 연산을 수행하도록 최적화할 수 있어 불필요한 연산을 줄입니다.
4. 다양한 명령어 집합
- AVX-512는 단순한 연산 외에도 정렬, 축소, 축적 같은 복잡한 연산들을 지원하여 데이터 변환과 같은 작업을 최적화할 수 있습니다.
- 이를 통해 기존의 명령어 세트로는 더 많은 연산이 필요했던 복잡한 벡터 연산을 더 빠르게 처리할 수 있습니다.
5. 더 나은 캐시 사용
- AVX-512를 사용하면 데이터 병렬성을 극대화하여 같은 데이터에 대해 연산을 수행하는 횟수를 줄일 수 있으므로, 캐시의 효율적인 활용이 가능합니다.
- 캐시 미스(cache miss)를 줄이고 더 많은 데이터를 한꺼번에 처리함으로써 메모리 대역폭 사용을 최적화할 수 있어 CPU와 메모리 간 병목 현상을 줄입니다.
요약
AVX-512는 벡터 길이를 늘리고 레지스터와 조건부 연산을 최적화하여 CPU가 더 많은 데이터를 동시에 처리할 수 있도록 하며, 이를 통해 벡터화된 병렬 작업을 극대화합니다. 특히 데이터 병렬성이 높은 연산에서는 성능이 큰 폭으로 향상될 수 있습니다.
요약
ffmpeg에 어셈블리를 통해 avx512를 적용한 결과 94배 빨라짐.
라이젠에서도 되나?
ZEN 4 부터 지원하는 거 같네여.
와 ㅎㄷㄷㄷ;;
어셈블리가 최고군
저런 확장 기능은 c, c++ 기본 문법으로는 사용할 수가 없어서 어셈블리를 써야 하니 신경써서 최적화 하지 않으면 적용이 안 되죠. 더군다나 어셈블리 할 줄 아는 개발자도 별로 없는 시대라 이런 게 신선한 뉴스가 되네여.
avx2도 64배는 늘은건가..