구글 연구소에서 신경망에 둠을 학습시켜 사람이 플레이할 수 있는 수준의 품질과 속도를 가진 인터랙티브 게임을 구현한 기술을 선보였습니다.
논문: https://arxiv.org/pdf/2408.14837
HN 토론: https://news.ycombinator.com/item?id=41375548
구글 번역
======
초록
우리는 긴 궤적에 걸쳐 복잡한 환경과 고품질로 실시간 상호작용을 가능하게 하는 신경 모델로 전적으로 구동되는 최초의 게임 엔진인 GameNGen을 소개합니다 . GameNGen은 단일 TPU에서 초당 20프레임 이상으로 고전 게임 DOOM을 대화형으로 시뮬레이션할 수 있습니다. 다음 프레임 예측은 손실이 있는 JPEG 압축과 비슷한 29.4의 PSNR을 달성합니다. 인간 평가자는 게임의 짧은 클립과 시뮬레이션 클립을 구별하는 데 있어 무작위 확률보다 약간 더 나을 뿐입니다. GameNGen은 두 단계로 훈련됩니다. (1) RL 에이전트가 게임을 하는 법을 배우고 훈련 세션을 기록합니다. (2) 확산 모델은 과거 프레임과 동작의 시퀀스에 따라 다음 프레임을 생성하도록 훈련됩니다. 조건 증강을 통해 긴 궤적에 걸쳐 안정적인 자기 회귀 생성이 가능합니다.
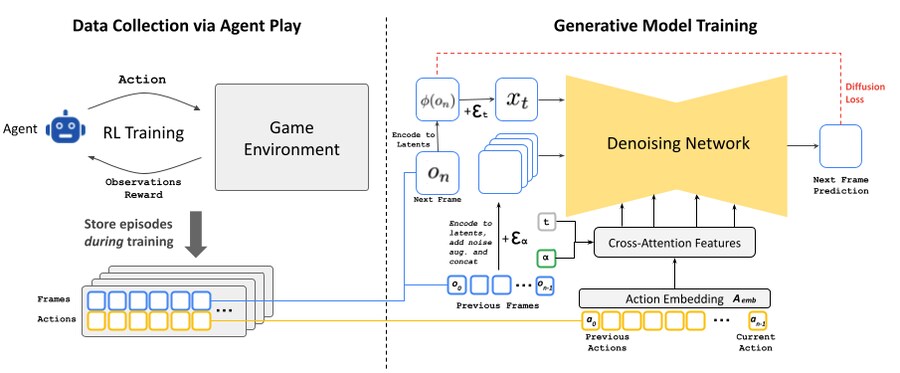
에이전트 플레이를 통한 데이터 수집: 인간의 게임 플레이를 대규모로 수집할 수 없으므로 첫 번째 단계로 자동 RL 에이전트가 게임을 플레이하도록 훈련하고, 행동과 관찰에 대한 훈련 에피소드를 유지합니다. 이는 생성 모델을 위한 훈련 데이터가 됩니다.
생성 확산 모델 훈련: 우리는 작은 확산 모델인 Stable Diffusion v1.4 를 재활용하고 , 이전의 액션과 관찰(프레임) 시퀀스에 따라 조건을 부여합니다. 추론 중에 자기 회귀 드리프트를 완화하기 위해, 훈련 중에 인코딩된 프레임에 가우시안 노이즈를 추가하여 컨텍스트 프레임을 손상시킵니다. 이를 통해 네트워크는 이전 프레임에서 샘플링된 정보를 수정할 수 있으며, 이는 장기간에 걸쳐 시각적 안정성을 유지하는 데 매우 중요하다는 것을 발견했습니다.
잠재 디코더 미세 조정: 8x8 픽셀 패치를 4개의 잠재 채널로 압축하는 Stable Diffusion v1.4 의 사전 학습된 자동 인코더는 게임 프레임을 예측할 때 의미 있는 아티팩트를 생성하여 작은 세부 사항과 특히 하단 막대 HUD에 영향을 미칩니다. 사전 학습된 지식을 활용하면서 이미지 품질을 개선하기 위해 대상 프레임 픽셀에 대해 계산된 MSE 손실을 사용하여 잠재 자동 인코더의 디코더만 학습합니다.
이왜둠? 😆